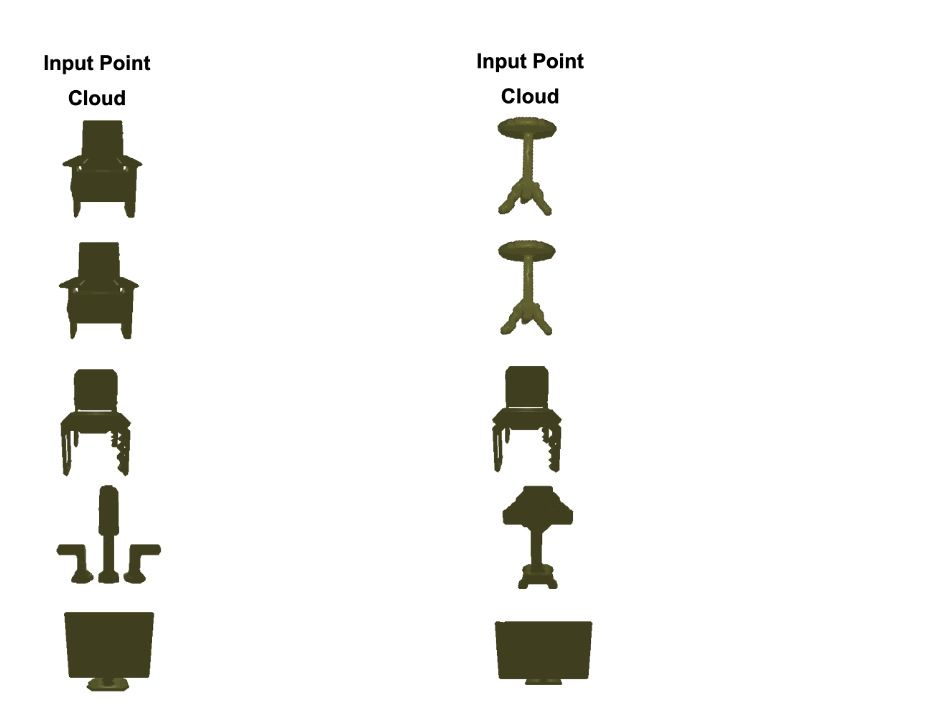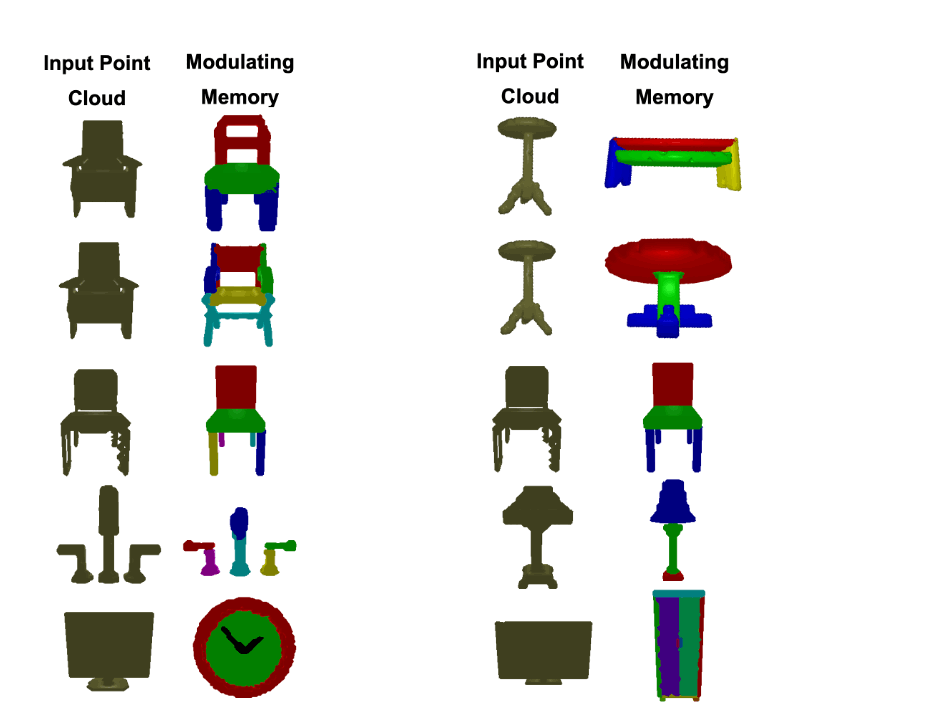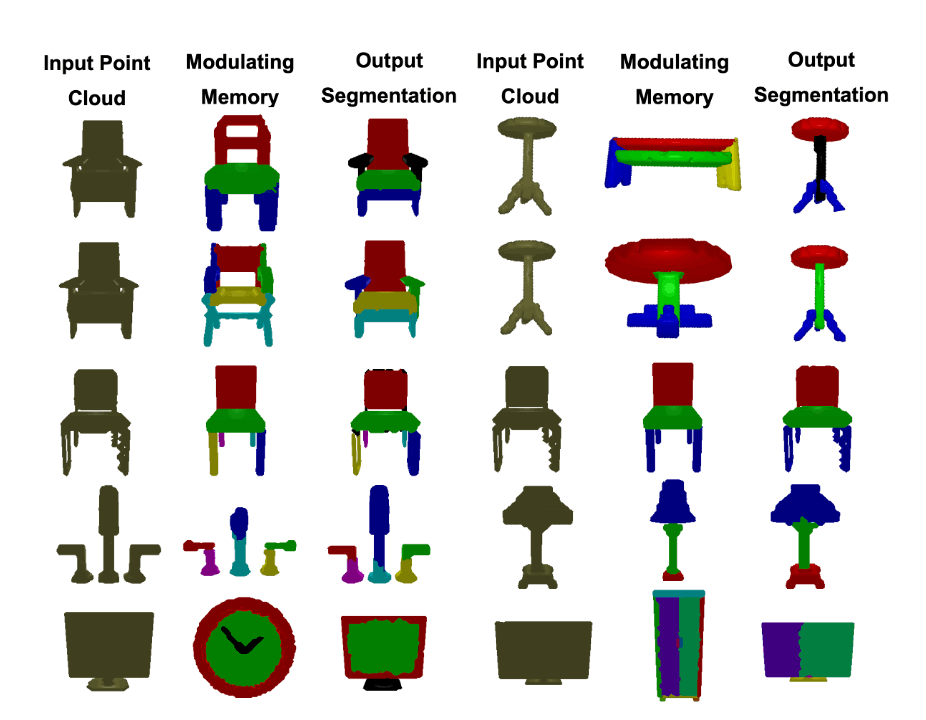
I am an Assistant Professor at Carnegie Mellon University in the Robotics Institute, where I am a part of the Computer Vision group. I am interested in building perception systems that can infer the spatial and physical structure of the world they observe. Please see these recenttalks for an overview.
Prior to joining CMU, I was a Research Scientist at FAIR, Pittsburgh working with Abhinav Gupta. I previously graduated from UC, Berkeley where I was advised by Jitendra Malik, and also frequently collaborated with Alyosha Efros.
email: shubhtuls AT cmu.edu
Office: Smith Hall 213
Research Group
Our group is interested in inferring physically and spatially grounded representations from perceptual input, and leveraging these for advances in fundamental problems in computer vision and robot manipulation. We are always looking for strongly motivated PhD and MS students. If you are interested in joining our group, please read this.
Dear Prospective Students,
Thanks for the interest in being a part of our group! Unfortunately, I am unable to reply to individual emails, but hope you find the following helpful:
I am a CMU student. How do I join your group?
Send me an email and/or drop by my office - I'd be happy to chat! If you are an undergraduate, also consider reaching out to the PhD students in our group if their projects align with your interests.
I want to join CMU. What graduate programs should I apply to?
PhD. Applicants: While I am primarily affiliated with RI, I can supervise students admitted in any SCS department (e.g. MLD, CSD) so apply to the department that best matches your interests and background. If you are interested in working with me, mention this in your application statement.
MS Applicants: RI offers MSR (research focused) and MSCV (industry focused) MS programs among others. Please apply to the program most aligned with your future goals.
Should I contact you before applying to CMU for admission?
Admissions across all PhD/MS programs are done by department-level committees and I am unable to help with individual applications. Please do feel free to reach out after you are admitted.
Are you accepting interns/visitors?
We do not have any short-term positions at this time.
Alumni PhD: Jason Zhang (co-advised with Deva Ramanan), Sparse-view 3D in the Wild, 2024. Google Yufei Ye (co-advised with Abhinav Gupta), Learning to Perceive and Predict Everyday Interactions, 2024. Postdoc at Stanford Homanga Bharadhwaj (co-advised with Abhinav Gupta), Watch, Predict, Act: Robot Learning meets Web Videos, 2025. Meta
[New]RayRoPE: Projective Ray Positional Encoding for Multi-view Attention
Yu Wu, Minsik Jeon, Jen-Hao Rick Chang, Oncel Tuzel, Shubham Tulsiani
ECCV, 2026 pdf project page bibtex code
@inproceedings{wu2026rayrope,
title={RayRoPE: Projective Ray Positional Encoding for Multi-view Attention},
author={Wu, Yu and Jeon, Minsik and Chang, Jen-Hao Rick and Tuzel, Oncel and Tulsiani, Shubham},
booktitle={European Conference on Computer Vision (ECCV)},
year={2026}
}
[New]GHOST: Hierarchical Sub-Goal Policies for Generalizing Robot Manipulation
Sriram Krishna, Ben Eisner, Haotian Zhan, Ying Yuan, Haoyu Zhen, Chuang Gan, Shubham Tulsiani, David Held
RSS, 2026 pdf project page bibtex code
@inproceedings{krishna2026ghost,
title={GHOST: Hierarchical Sub-Goal Policies for Generalizing Robot Manipulation},
author={Krishna, Sriram and Eisner, Ben and Zhan, Haotian and Yuan, Ying and Zhen, Haoyu and Gan, Chuang and Tulsiani, Shubham and Held, David},
booktitle={Robotics: Science and Systems (RSS)},
year={2026}
}
[New]Temporal Score Rescaling for Temperature Sampling in Diffusion and Flow Models
Yanbo Xu, Yu Wu, Sungjae Park, Zhizhuo Zhou, Shubham Tulsiani
ICML, 2026 pdf project page bibtex code
@inproceedings{xu2026temporal,
title={Temporal Score Rescaling for Temperature Sampling in Diffusion and Flow Models},
author={Xu, Yanbo and Wu, Yu and Park, Sungjae and Zhou, Zhizhuo and Tulsiani, Shubham},
booktitle={International Conference on Machine Learning (ICML)},
year={2026}
}
@inproceedings{cong2026flow3r,
title={Flow3r: Factored Flow Prediction for Scalable Visual Geometry Learning},
author={Cong, Zhongxiao and Zhao, Qitao and Jeon, Minsik and Tulsiani, Shubham},
booktitle={CVPR},
year={2026}
}
[New]E-RayZer: Self-supervised 3D Reconstruction as Spatial Visual Pre-training
Qitao Zhao, Hao Tan, Qianqian Wang, Sai Bi, Kai Zhang, Kalyan Sunkavalli, Shubham Tulsiani*, Hanwen Jiang*
CVPR, 2026 pdf project page bibtex code
@inproceedings{zhao2026erayzer,
title={E-RayZer: Self-supervised 3D Reconstruction as Spatial Visual Pre-training},
author={Zhao, Qitao and Tan, Hao and Wang, Qianqian and Bi, Sai and Zhang, Kai and Sunkavalli, Kalyan and Tulsiani, Shubham and Jiang, Hanwen},
booktitle={CVPR},
year={2026}
}
[New]EditCtrl: Disentangled Local and Global Control for Real-Time Generative Video Editing
Yehonathan Litman, Shikun Liu, Dario Seyb, Nicholas Milef, Yang Zhou, Carl Marshall, Shubham Tulsiani, Caleb Leak
CVPR, 2026 pdf project page bibtex code
@inproceedings{litman2026editctrl,
title={EditCtrl: Disentangled Local and Global Control for Real-Time Generative Video Editing},
author={Litman, Yehonathan and Liu, Shikun and Seyb, Dario and Milef, Nicholas and Zhou, Yang and Marshall, Carl and Tulsiani, Shubham and Leak, Caleb},
booktitle={CVPR},
year={2026}
}
DemoDiffusion: One-Shot Human Imitation using Pre-trained Diffusion Policy
Sungjae Park, Homanga Bharadhwaj, Shubham Tulsiani
ICRA, 2026 pdf project page bibtex code
@inProceedings{park2026demodiffusion,
title={DemoDiffusion: One-Shot Human Imitation using Pre-trained Diffusion Policy},
author={Park, Sungjae and Bharadhwaj, Homanga and Tulsiani, Shubham},
year={2026},
booktitle={IEEE International Conference on Robotics and Automation (ICRA)}
}
CRISP: Contact-Guided Real2Sim from Monocular Video with Planar Scene Primitives
Zihan Wang, Jiashun Wang, Jeff Tan, Yiwen Zhao, Jessica Hodgins, Shubham Tulsiani, Deva Ramanan
ICLR, 2026 pdf project page bibtex code
@inProceedings{wang2026crisp,
title={CRISP: Contact-Guided Real2Sim from Monocular Video with Planar Scene Primitives},
author={Wang, Zihan and Wang, Jiashun and Tan, Jeff and Zhao, Yiwen and Hodgins, Jessica and Tulsiani, Shubham and Ramanan, Deva},
year={2026},
booktitle={International Conference on Learning Representations (ICLR)}
}
Predicting 4D Hand Trajectory from Monocular Videos
Yufei Ye, Yao Feng, Omid Taheri, Haiwen Feng, Shubham Tulsiani, Michael J. Black
3DV, 2026 pdf project page bibtex code
@inProceedings{ye2026haptic,
title={Predicting 4D Hand Trajectory from Monocular Videos},
author={Ye, Yufei and Feng, Yao and Taheri, Omid and Feng, Haiwen and Tulsiani, Shubham and Black, Michael J.},
year={2026},
booktitle={International Conference on 3D Vision (3DV)}
}
2025
LightSwitch: Multi-view Relighting with Material-guided Diffusion
Yehonathan Litman, Fernando De la Torre, Shubham Tulsiani
ICCV, 2025 pdf project page bibtex code
@inproceedings{litman2025lightswitch,
title={LightSwitch: Multi-view Relighting with Material-guided Diffusion},
author={Yehonathan Litman and Fernando De la Torre and Shubham Tulsiani},
booktitle = {ICCV},
year={2025}
}
Gen2Act: Human Video Generation in Novel Scenarios enables Generalizable Robot Manipulation
Homanga Bharadhwaj, Debidatta Dwibedi, Abhinav Gupta, Shubham Tulsiani, Carl Doersch, Ted Xiao, Dhruv Shah, Fei Xia, Dorsa Sadigh, Sean Kirmani
CoRL, 2025 pdf project page bibtex
@inProceedings{bharadhwaj2025gen2act,
title={Gen2Act: Human Video Generation in Novel Scenarios enables Generalizable Robot Manipulation},
author={Bharadhwaj, Homanga and Dwibedi, Debidatta and Gupta, Abhinav and Tulsiani, Shubham and Doersch, Carl and Xiao, Ted and Shah, Dhruv and Xia, Fei and Sadigh, Dorsa and Kirmani, Sean},
year={2025},
booktitle={Conference on Robot Learning (CoRL)}
}
DiffusionSfM: Predicting Structure and Motion via Ray Origin and Endpoint Diffusion
Qitao Zhao, Amy Lin, Jeff Tan, Jason Y. Zhang, Deva Ramanan, Shubham Tulsiani
CVPR, 2025 pdf project page bibtex code
@inproceedings{zhao2025diffusionsfm,
title={DiffusionSfM: Predicting Structure and Motion via Ray Origin and Endpoint Diffusion},
author={Qitao Zhao and Amy Lin and Jeff Tan and Jason Y. Zhang and Deva Ramanan and Shubham Tulsiani},
booktitle={CVPR},
year={2025}
}
UniPhy: Learning a Unified Constitutive Model for Inverse Physics Simulation
Himangi Mittal, Peiye Zhuang, Hsin-Ying Lee, Shubham Tulsiani
CVPR, 2025 pdf project page bibtex code
@inproceedings{mittal2025uniphy,
title={UniPhy: Learning a Unified Constitutive Model for Inverse Physics Simulation},
author={Mittal, Himangi and Zhuang, Peiye and Lee, Hsin-Ying and Tulsiani, Shubham},
booktitle={CVPR},
year={2025}
}
AerialMegaDepth: Learning Aerial-Ground Reconstruction and View Synthesis
Khiem Vuong, Anurag Ghosh, Deva Ramanan*, Srinivasa Narasimhan*, Shubham Tulsiani*
CVPR, 2025 pdf project page bibtex code
@inproceedings{vuong2025aerialmegadepth,
title={AerialMegaDepth: Learning Aerial-Ground Reconstruction and View Synthesis},
author={Vuong, Khiem and Ghosh, Anurag and Ramanan, Deva and Narasimhan, Srinivasa and Tulsiani, Shubham},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2025},
}
Turbo3D: Ultra-fast Text-to-3D Generation
Hanzhe Hu, Tianwei Yin, Fujun Luan, Yiwei Hu, Hao Tan, Zexiang Xu, Sai Bi, Shubham Tulsiani*, Kai Zhang*
CVPR, 2025 pdf project page bibtex
@inproceedings{huturbo3d,
title={Turbo3D: Ultra-fast Text-to-3D Generation},
author={Hanzhe Hu and Tianwei Yin and Fujun Luan and Yiwei Hu and Hao Tan and Zexiang Xu and Sai Bi and Shubham Tulsiani and Kai Zhang},
booktitle={CVPR},
year={2025}
}
SceneFactor: Factored Latent 3D Diffusion for Controllable 3D Scene Generation
Alexey Bokhovkin, Quan Meng, Shubham Tulsiani, Angela Dai
CVPR, 2025 pdf project page bibtex code
@inproceedings{bokhovkin2025scenefactor,
title={SceneFactor: Factored Latent 3D Diffusion for Controllable 3D Scene Generation},
author={Bokhovkin, Alexey and Meng, Quan and Tulsiani, Shubham and Dai, Angela},
booktitle={CVPR},
year={2025}
}
MaterialFusion: Enhancing Inverse Rendering with Material Diffusion Priors
Yehonathan Litman, Or Patashnik, Kangle Deng, Aviral Agrawal, Rushikesh Zawar, Fernando De la Torre, Shubham Tulsiani
3DV, 2025 pdf project page bibtex code
@inproceedings{litman2025materialfusion,
author = {Yehonathan Litman and Or Patashnik and Kangle Deng and Aviral Agrawal and Rushikesh Zawar and Fernando De la Torre and Shubham Tulsiani},
title = {MaterialFusion: Enhancing Inverse Rendering with Material Diffusion Priors},
booktitle = {3DV},
year = {2025}
}
DressRecon: Freeform 4D Human Reconstruction from Monocular Video
Jeff Tan, Donglai Xiang, Shubham Tulsiani, Deva Ramanan, Gengshan Yang
3DV, 2025 pdf project page bibtex code
@inproceedings{tan2024dressrecon,
title={DressRecon: Freeform 4D Human Reconstruction from Monocular Video},
author={Tan, Jeff and Xiang, Donglai and Tulsiani, Shubham and Ramanan, Deva and Yang, Gengshan},
booktitle = {3DV},
year = {2025}
}
2024
Sparse-view Pose Estimation and Reconstruction via Analysis by Generative Synthesis
Qitao Zhao, Shubham Tulsiani
NeurIPS, 2024 pdf project page bibtex code
@inproceedings{bharadhwaj2024track2act,
author = {Homanga Bharadhwaj and Roozbeh Mottaghi and Abhinav Gupta and Shubham Tulsiani},
title = {Track2Act: Predicting Point Tracks from Internet Videos enables Diverse Zero-shot Robot Manipulation},
booktitle={European Conference on Computer Vision (ECCV)},
year = {2024}
}
Track2Act: Predicting Point Tracks from Internet Videos Enables Diverse Zero-shot Manipulation
Homanga Bharadhwaj, Roozbeh Mottaghi*, Abhinav Gupta*, Shubham Tulsiani*
ECCV, 2024 pdf project page bibtex code
@inproceedings{bharadhwaj2024track2act,
author = {Homanga Bharadhwaj and Roozbeh Mottaghi and Abhinav Gupta and Shubham Tulsiani},
title = {Track2Act: Predicting Point Tracks from Internet Videos enables Diverse Zero-shot Robot Manipulation},
booktitle={European Conference on Computer Vision (ECCV)},
year = {2024}
}
@inproceedings{kani24upfusion,
author = {Nagoor Kani, Bharath Raj and Lee, Hsin-Ying and Tulyakov, Sergey and Tulsiani, Shubham},
title = {UpFusion: Novel View Diffusion from Unposed Sparse View Observations},
booktitle={European Conference on Computer Vision (ECCV)},
year = {2024}
}
G-HOP: Generative Hand-Object Prior for Interaction Reconstruction and Grasp Synthesis
Yufei Ye, Abhinav Gupta, Kris Kitani, Shubham Tulsiani
CVPR, 2024 pdf project page bibtex code
@inproceedings{ye2024ghop,
author = {Ye, Yufei and Gupta, Abhinav and Kitani, Kris and Tulsiani, Shubham}
title = {G-HOP: Generative Hand-Object Prior for Interaction Reconstruction and Grasp Synthesis},
booktitle={CVPR},
year={2024}
}
MVD-Fusion: Single-view 3D via Depth-consistent Multi-view Generation
Hanzhe Hu*, Zhizhuo Zhou*, Varun Jampani, Shubham Tulsiani
CVPR, 2024 pdf project page bibtex code
@inproceedings{hu2024mvdfusion,
title={MVD-Fusion: Single-view 3D via Depth-consistent Multi-view Generation},
author={Hanzhe Hu and Zhizhuo Zhou and Varun Jampani and Shubham Tulsiani},
booktitle={CVPR},
year={2024}
}
Cameras as Rays: Pose Estimation via Ray Diffusion
Jason Y. Zhang*, Amy Lin*, Moneish Kumar, Tzu-Hsuan Yang, Deva Ramanan, Shubham Tulsiani
ICLR, 2024 pdf project page bibtex code
@InProceedings{zhang2024raydiffusion,
title={Cameras as Rays: Pose Estimation via Ray Diffusion},
author={Zhang, Jason Y and Lin, Amy and Kumar, Moneish and Yang, Tzu-Hsuan and Ramanan, Deva and Tulsiani, Shubham},
booktitle={International Conference on Learning Representations (ICLR)},
year={2024}
}
Towards Generalizable Zero-Shot Manipulation via Translating Human Interaction Plans
Homanga Bharadhwaj, Abhinav Gupta*, Vikash Kumar*, Shubham Tulsiani*
ICRA, 2024 (Finalist for Best Paper Award in Robot Manipulation) pdf project page bibtex
@article{bharadhwaj2023towards,
title={Towards Generalizable Zero-Shot Manipulation via Translating Human Interaction Plans},
author={Bharadhwaj, Homanga and Gupta, Abhinav and Kumar, Vikash and Tulsiani, Shubham},
journal={arXiv preprint arXiv:2312.00775},
year={2023}
}
RoboAgent: Towards Sample Efficient Robot Manipulation with Semantic Augmentations and Action Chunking
Homanga Bharadhwaj*, Jay Vakil*, Mohit Sharma*, Abhinav Gupta, Shubham Tulsiani, Vikash Kumar
ICRA, 2024 pdf project page bibtex data
@article{bharadhwaj2023roboagent,
title={Roboagent: Generalization and efficiency in robot manipulation via semantic augmentations and action chunking},
author={Bharadhwaj, Homanga and Vakil, Jay and Sharma, Mohit and Gupta, Abhinav and Tulsiani, Shubham and Kumar, Vikash},
journal={arXiv preprint arXiv:2309.01918},
year={2023}
}
RelPose++: Recovering 6D Poses from Sparse-view Observations
Amy Lin*, Jason Y. Zhang*, Deva Ramanan, Shubham Tulsiani
3DV, 2024 pdf project page bibtex code
@inproceedings{lin2024relposepp,
title={RelPose++: Recovering 6D Poses from Sparse-view Observations},
author={Lin, Amy and Zhang, Jason Y and Ramanan, Deva and Tulsiani, Shubham},
booktitle={3DV},
year={2024}
}
2023
Diffusion-Guided Reconstruction of Everyday Hand-Object Interaction Clips
Yufei Ye, Poorvi Hebbar, Abhinav Gupta, Shubham Tulsiani
ICCV, 2023 pdf project page bibtex code
@inproceedings{ye2023vhoi,
author = {Ye, Yufei and Hebbar, Poorvi and Gupta, Abhinav and Tulsiani, Shubham}
title = {Diffusion-Guided Reconstruction of Everyday Hand-Object Interaction Clips},
booktitle = {ICCV},
year = {2023}
}
Manipulate by Seeing: Creating Manipulation Controllers from Pre-Trained Representations
Jianren Wang*, Sudeep Dasari*, Mohan Kumar Srirama, Shubham Tulsiani, Abhinav Gupta
ICCV, 2023 pdf project page bibtex code
@article{wang2023manipulate,
title={Manipulate by Seeing: Creating Manipulation Controllers from Pre-Trained Representations},
author={Wang, Jianren and Dasari, Sudeep and Srirama, Mohan Kumar and Tulsiani, Shubham and Gupta, Abhinav},
booktitle={International Conference on Computer Vision (ICCV)},
year={2023}
}
Mesh2Tex: Generating Mesh Textures from Image Queries
Alexey Bokhovkin, Shubham Tulsiani, Angela Dai
ICCV, 2023 pdf project page bibtex
@inproceedings{ye2023vhoi,
title = {Mesh2Tex: Generating Mesh Textures from Image Queries},
author = {Bokhovkin, Alexey and Tulsiani, Shubham and Dai, Angela},
booktitle = {ICCV},
year = {2023}
}
Visual Affordance Prediction for Guiding Robot Exploration
Homanga Bharadhwaj, Abhinav Gupta, Shubham Tulsiani
ICRA, 2023 pdf project page bibtex code
@article{BharadhwajVisual,
Author = {Homanga Bharadhwaj and Abhinav Gupta and Shubham Tulsiani},
Journal={IEEE International Conference on Robotics and Automation (ICRA)},
Year = {2023},
Title = {Visual Affordance Prediction for Guiding Robot Exploration}
}
Analogy-Forming Transformers for Few-Shot 3D Parsing
Nikolaos Gkanatsios*, Mayank Singh*, Zhaoyuan Fang, Shubham Tulsiani, Katerina Fragkiadaki
ICLR, 2023 pdf project page bibtex code
@article{gkanatsios2023analogical,
author = {Gkanatsios, Nikolaos and Singh, Mayank and Fang, Zhaoyuan and Tulsiani, Shubham and Fragkiadaki, Katerina},
title = {Analogy-Forming Transformers for Few-Shot 3D Parsing},
journal = {ICLR},
year = {2023},
}
SparseFusion: Distilling View-conditioned Diffusion for 3D Reconstruction
Zhizhuo Zhou, Shubham Tulsiani
CVPR, 2023 pdf project page bibtex code
@inproceedings{zhou2023sparsefusion,
title={SparseFusion: Distilling View-conditioned Diffusion for 3D Reconstruction},
author={Zhizhuo Zhou and Shubham Tulsiani},
booktitle={CVPR},
year={2023}
}
Affordance Diffusion: Synthesizing Hand-Object Interactions
Yufei Ye, Xueting Li, Abhinav Gupta, Shalini De Mello, Stan Birchfield, Jiaming Song, Shubham Tulsiani, Sifei Liu
CVPR, 2023 pdf project page bibtex
@inproceedings{ye2023affordance,
title={Affordance Diffusion: Synthesizing Hand-Object Interactions},
author={Yufei Ye and Xueting Li and Abhinav Gupta and Shalini De Mello and Stan Birchfield, Jiaming Song and Shubham Tulsiani and Sifei Liu},
booktitle={CVPR},
year={2023}
}
2022
Monocular Dynamic View Synthesis: A Reality Check
Hang Gao, Ruilong Li, Shubham Tulsiani, Bryan Russell, Angjoo Kanazawa
NeurIPS, 2022 pdf project page bibtex code
@inproceedings{gao2022dynamic,
title={Monocular Dynamic View Synthesis: A Reality Check},
author={Gao, Hang and
Li, Ruilong and
Tulsiani, Shubham and
Russell, Bryan and
Kanazawa, Angjoo},
booktitle={NeurIPS},
year={2022},
}
RelPose: Predicting Probabilistic Relative Rotation for Single Objects in the Wild
Jason Y. Zhang, Deva Ramanan, Shubham Tulsiani
ECCV, 2022 pdf project page bibtex code
@InProceedings{zhang2022relpose,
title = {{RelPose}: Predicting Probabilistic Relative Rotation for Single Objects in the Wild},
author = {Zhang, Jason Y. and Ramanan, Deva and Tulsiani, Shubham},
booktitle = {European Conference on Computer Vision},
year = {2022}
}
Pre-train, Self-train, Distill: A simple recipe for Supersizing 3D Reconstruction
Kalyan Vasudev Alwala, Abhinav Gupta, Shubham Tulsiani
CVPR, 2022 pdf project page bibtex code
@inProceedings{vasudev2022ss3d,
title={Pre-train, Self-train, Distill: A simple recipe for Supersizing 3D Reconstruction},
author={Alwala, Kalyan Vasudev and Gupta, Abhinav and Tulsiani, Shubham},
year={2022},
booktitle={Computer Vision and Pattern Recognition (CVPR)}
}
What's in your hands? 3D Reconstruction of Generic Objects in Hands
Yufei Ye, Abhinav Gupta, Shubham Tulsiani
CVPR, 2022 pdf project page bibtex code
@inProceedings{ye2022ihoi,
title={What's in your hands? 3D Reconstruction of Generic Objects in Hands},
author={Ye, Yufei and Gupta, Abhinav and Tulsiani, Shubham},
year={2022},
booktitle={Computer Vision and Pattern Recognition (CVPR)}
}
AutoSDF: Shape Priors for 3D Completion, Reconstruction and Generation
Paritosh Mittal*, Yen-Chi Cheng*, Maneesh Singh, Shubham Tulsiani
CVPR, 2022 pdf project page bibtex code
@inproceedings{autosdf2022,
title={{AutoSDF}: Shape Priors for 3D Completion, Reconstruction and Generation},
author={Mittal, Paritosh and Cheng, Yen-Chi and Singh, Maneesh and Tulsiani, Shubham},
booktitle={CVPR},
year={2022}
}
2021
NeRS: Neural Reflectance Surfaces for Sparse-view 3D Reconstruction in the Wild
Jason Y. Zhang, Gengshan Yang, Shubham Tulsiani*, and Deva Ramanan*
NeurIPS, 2021 pdf project page bibtex video code
@inproceedings{zhang2021ners,
title={{NeRS}: Neural Reflectance Surfaces for Sparse-view 3D Reconstruction in the Wild},
author={Zhang, Jason Y. and Yang, Gengshan and Tulsiani, Shubham and Ramanan, Deva},
booktitle={Conference on Neural Information Processing Systems},
year={2021}
}
No RL, No Simulation: Learning to Navigate without Navigating
Meera Hahn, Devendra Chaplot, Shubham Tulsiani, Mustafa Mukadam, James M. Rehg, Abhinav Gupta
NeurIPS, 2021 pdf project page bibtex code
@article{hahn2021nrns,
title={No RL, No Simulation: Learning to Navigate without Navigating},
author={Meera Hahn and Devendra Chaplot and Shubham Tulsiani and Mustafa Mukadam and James Rehg and Abhinav Gupta},
booktitle={Neural Information Processing Systems},
year={2021},
}
A Differentiable Recipe for Learning Visual Non-Prehensile Planar Manipulation
Bernardo Aceituno, Alberto Rodriguez, Shubham Tulsiani, Abhinav Gupta, Mustafa Mukadam
CoRL, 2021 pdf bibtex
@inProceedings{aceituno21planar,
title={A Differentiable Recipe for Learning Visual Non-Prehensile Planar Manipulation},
author={Aceituno, Bernardo and Rodriguez, Alberto and Tulsiani, Shubham and Gupta, Abhinav and Mukadam, Mustafa},
year={2021},
booktitle={Conference on Robot Learning (CoRL)}
}
Where2Act: From Pixels to Actions for Articulated 3D Objects
Kaichun Mo, Leonidas J. Guibas, Mustafa Mukadam, Abhinav Gupta, Shubham Tulsiani
ICCV, 2021 pdf bibtex code
@inProceedings{mo2021where2act,
title={Where2Act: From Pixels to Actions for Articulated 3D Objects},
author={Mo, Kaichun and Guibas, Leonidas and Mukadam, Mustafa and Gupta, Abhinav and Tulsiani, Shubham},
year={2021},
booktitle={International Conference on Computer Vision (ICCV)}
}
PixelTransformer: Sample Conditioned Signal Generation Shubham Tulsiani, Abhinav Gupta
ICML, 2021 pdf project page bibtex code
@inProceedings{tulsiani2021pixel,
title={PixelTransformer: Sample Conditioned Signal Generation},
author={Tulsiani, Shubham and Gupta, Abhinav},
year={2021},
booktitle={International Conference on Machine Learning (ICML)}
}
Shelf-Supervised Mesh Prediction in the Wild
Yufei Ye, Shubham Tulsiani, Abhinav Gupta
CVPR, 2021 pdf project page bibtex code
@inProceedings{ye2021shelf,
title={Shelf-Supervised Mesh Prediction in the Wild},
author={Ye, Yufei and Tulsiani, Shubham and Gupta, Abhinav},
year={2021},
booktitle={Computer Vision and Pattern Recognition (CVPR)}
}
2020
See, Hear, Explore: Curiosity via Audio-Visual Association
Victoria Dean, Shubham Tulsiani, Abhinav Gupta
NeurIPS, 2020 pdf project page bibtex video code
@article{dean2020see,
title={See, hear, explore: Curiosity via audio-visual association},
author={Dean, Victoria and Tulsiani, Shubham and Gupta, Abhinav},
journal={Advances in Neural Information Processing Systems},
volume={33},
year={2020}
}
Visual Imitation Made Easy
Sarah Young, Dhiraj Gandhi, Shubham Tulsiani, Abhinav Gupta, Pieter Abbeel, Lerrel Pinto
CORL, 2020 pdf project page bibtex video code
@inProceedings{young2020vime,
title={Visual Imitation Made Easy},
author={Young, Sarah and Gandhi, Dhiraj and Tulsiani, Shubham and Gupta, Abhinav and Abbeel, Pieter and Pinto, Lerrel},
year={2020},
booktitle={Conference on Robot Learning (CORL)}
}
Articulation-aware Canonical Surface Mapping
Nilesh Kulkarni, Abhinav Gupta, David Fouhey, Shubham Tulsiani
CVPR, 2020 pdf project page bibtex video code
@inProceedings{kulkarni2020acsm,
title={Articulation-aware Canonical Surface Mapping},
author={Kulkarni, Nilesh and Gupta, Abhinav and Fouhey, David and Tulsiani, Shubham},
year={2020},
booktitle={Computer Vision and Pattern Recognition (CVPR)}
}
Use the Force, Luke! Learning to Predict Physical Forces by Simulating Effects
Kiana Ehsani, Shubham Tulsiani, Saurabh Gupta, Ali Farhadi, Abhinav Gupta
CVPR, 2020 pdf project page bibtex code
@inProceedings{ehsani2020force,
title={Use the Force, Luke! Learning to Predict Physical Forces by Simulating Effects},
author={Ehsani, Kiana and Tulsiani, Shubham and Gupta, Saurabh and Farhadi, Ali and Gupta, Abhinav},
year={2020},
booktitle={Computer Vision and Pattern Recognition (CVPR)}
}
Intrinsic Motivation for Encouraging Synergistic Behavior
Rohan Chitnis, Shubham Tulsiani, Saurabh Gupta, Abhinav Gupta
ICLR, 2020 pdf project page bibtex
@inproceedings{chitnis20synergy,
title={Intrinsic Motivation for Encouraging Synergistic Behavior},
author={Chitnis, Rohan and Tulsiani, Shubham and Gupta, Saurabh and Gupta, Abhinav},
booktitle={ICLR},
year={2020}
}
Discovering Motor Programs by Recomposing Demonstrations
Tanmay Shankar, Shubham Tulsiani, Lerrel Pinto, Abhinav Gupta
ICLR, 2020 pdf bibtex
@inproceedings{shankar20motor,
title={Discovering Motor Programs by Recomposing Demonstrations},
author={Shankar, Tanmay and Tulsiani, Shubham and Pinto, Lerrel and Gupta, Abhinav},
booktitle={ICLR},
year={2020}
}
Efficient Bimanual Manipulation using Learned Task Schemas
Rohan Chitnis, Shubham Tulsiani, Saurabh Gupta, Abhinav Gupta
ICRA, 2020 preprint bibtex video
@inproceedings{chitnis20schema,
title={Efficient Bimanual Manipulation Using Learned Task Schemas},
author={Chitnis, Rohan and Tulsiani, Shubham and Gupta, Saurabh and Gupta, Abhinav},
booktitle={ICRA},
year={2020}
}
2019
Object-centric Forward Modeling for Model Predictive Control
Yufei Ye, Dhiraj Gandhi, Abhinav Gupta, Shubham Tulsiani
CORL, 2019 pdf project page bibtex
@inProceedings{ye2019ocm,
title={Object-centric Forward Modeling for Model Predictive Control},
author={Ye, Yufei and Gandhi, Dhiraj and Gupta, Abhinav and Tulsiani, Shubham},
year={2019},
booktitle={Conference on Robot Learning (CORL)}
}
Canonical Surface Mapping via Geometric Cycle Consistency
Nilesh Kulkarni, Abhinav Gupta*, Shubham Tulsiani*
ICCV, 2019 pdf project page bibtex video code
@inProceedings{kulkarni2019csm,
title={Canonical Surface Mapping via Geometric Cycle Consistency},
author={Kulkarni, Nilesh and Gupta, Abhinav and Tulsiani, Shubham},
year={2019},
booktitle={International Conference on Computer Vision (ICCV)}
}
Compositional Video Prediction
Yufei Ye, Maneesh Singh, Abhinav Gupta*, Shubham Tulsiani*
ICCV, 2019 pdf project page bibtex code
@inProceedings{ye2019cvp,
title={Compositional Video Prediction},
author={Ye, Yufei and Singh, Maneesh and Gupta, Abhinav and Tulsiani, Shubham},
year={2019},
booktitle={International Conference on Computer Vision (ICCV)}
}
3D-RelNet: Joint Object and Relational Network for 3D Prediction
Nilesh Kulkarni, Ishan Misra, Shubham Tulsiani, Abhinav Gupta
ICCV, 2019 pdf project page bibtex code
@inProceedings{kulkarni2019relnet,
title={3D-RelNet: Joint Object and Relational Network for 3D Prediction},
author={Nilesh Kulkarni, Ishan Misra, Shubham Tulsiani, Abhinav Gupta},
booktitle={ICCV},
year={2019}
}
Order-Aware Generative Modeling Using the 3D-Craft Dataset
Zhuoyuan Chen*, Demi Guo*, Tong Xiao*, et. al.
ICCV, 2019 pdf bibtex
@inProceedings{chen2019craft,
title={Order-Aware Generative Modeling Using the 3D-Craft Dataset},
author={Zhuoyuan Chen, Demi Guo, Tong Xiao, Saining Xie, Xinlei Chen, Haonan Yu, Jonathan Gray, Kavya Srinet, Haoqi Fan, Jerry Ma, Charles R. Qi, Shubham Tulsiani, Arthur Szlam, and C. Lawrence Zitnick},
booktitle={ICCV},
year={2019}
}
Learning Unsupervised Multi-View Stereopsis via Robust Photometric Consistency
Tejas Khot*, Shubham Agrawal*, Shubham Tulsiani, Christoph Mertz, Simon Lucey, Martial Hebert
arXiv preprint, 2019 pdf project page bibtex code
@article{khot2019learning,
title={Learning Unsupervised Multi-View Stereopsis via Robust Photometric Consistency},
author={Khot, Tejas and Agrawal, Shubham and Tulsiani, Shubham and Mertz, Christoph and Lucey, Simon and Hebert, Martial},
journal={arXiv preprint arXiv:1905.02706},
year={2019}
}
2018
Layer-structured 3D Scene Inference via View Synthesis Shubham Tulsiani, Richard Tucker, Noah Snavely
ECCV, 2018 pdf project page bibtex code
@inProceedings{lsiTulsiani18,
title={Layer-structured 3D Scene Inference via View Synthesis},
author = {Shubham Tulsiani
and Richard Tucker
and Noah Snavely},
booktitle={ECCV},
year={2018}
}
Learning Category-Specific Mesh Reconstruction from Image Collections
Angjoo Kanazawa*, Shubham Tulsiani*, Alexei A. Efros, Jitendra Malik
ECCV, 2018 pdf project page bibtex video code
@inProceedings{cmrKanazawa18,
title={Learning Category-Specific Mesh Reconstruction
from Image Collections},
author = {Angjoo Kanazawa and
Shubham Tulsiani
and Alexei A. Efros
and Jitendra Malik},
booktitle={ECCV},
year={2018}
}
Multi-view Consistency as Supervisory Signal for Learning Shape and Pose Prediction Shubham Tulsiani, Alexei A. Efros, Jitendra Malik
CVPR, 2018 pdf project page bibtex code
@inProceedings{mvcTulsiani18,
title={Multi-view Consistency as Supervisory Signal
for Learning Shape and Pose Prediction},
author = {Shubham Tulsiani
and Alexei A. Efros
and Jitendra Malik},
booktitle={Computer Vision and Pattern Recognition (CVPR)},
year={2018}
}
Factoring Shape, Pose, and Layout from the 2D Image of a 3D Scene Shubham Tulsiani, Saurabh Gupta, David Fouhey, Alexei A. Efros, Jitendra Malik
CVPR, 2018 pdf project page bibtex code
@inProceedings{factored3dTulsiani17,
title={Factoring Shape, Pose, and Layout from the 2D Image of a 3D Scene},
author = {Shubham Tulsiani
and Saurabh Gupta
and David Fouhey
and Alexei A. Efros
and Jitendra Malik},
booktitle={Computer Vision and Pattern Recognition (CVPR)},
year={2018}
}
2017
Multi-view Supervision for Single-view Reconstruction via Differentiable Ray Consistency Shubham Tulsiani, Tinghui Zhou, Alexei A. Efros, Jitendra Malik
CVPR, 2017 pdf project page bibtex slides talk code blog post
@inProceedings{drcTulsiani17,
title={Multi-view Supervision for Single-view Reconstruction
via Differentiable Ray Consistency},
author = {Shubham Tulsiani
and Tinghui Zhou
and Alexei A. Efros
and Jitendra Malik},
booktitle={Computer Vision and Pattern Recognition (CVPR)},
year={2017}
}
@inProceedings{abstractionTulsiani17,
title={Learning Shape Abstractions by Assembling Volumetric Primitives},
author = {Shubham Tulsiani
and Hao Su
and Leonidas J. Guibas
and Alexei A. Efros
and Jitendra Malik},
booktitle={Computer Vision and Pattern Recognition (CVPR)},
year={2017}
}
Hierarchical Surface Prediction for 3D Object Reconstruction
Christian Häne, Shubham Tulsiani, Jitendra Malik
3DV, 2017 pdf bibtex slides code
@incollection{hspHane17,
author = {Christian H{\"a}ne and
Shubham Tulsiani and
Jitendra Malik},
title = {Hierarchical Surface Prediction for 3D Object Reconstruction},
booktitle = {arXiv preprint arXiv:1704.00710},
year = {2017}
}
2016
Learning Category-Specific Deformable 3D Models for Object Reconstruction Shubham Tulsiani*, Abhishek Kar*, João Carreira, Jitendra Malik
TPAMI, 2016 pdf bibtex code
@article{pamishapeTulsianiKCM15,
author = {Shubham Tulsiani and
Abhishek Kar and
Jo{\~{a}}o Carreira and
Jitendra Malik},
title = {Learning Category-Specific Deformable 3D
Models for Object Reconstruction},
journal = {TPAMI},
year = {2016},
}
View Synthesis by Appearance Flow
Tinghui Zhou, Shubham Tulsiani, Weilun Sun, Jitendra Malik, Alexei A. Efros
ECCV, 2016 pdf bibtex code
@incollection{appFlowZhou16,
author = {Tinghui Zhou and
Shubham Tulsiani and
Weilun Sun and
Jitendra Malik and
Alexei A. Efros},
title = {View Synthesis by Appearance Flow},
booktitle = {ECCV},
year = {2016}
}
2015
Pose Induction for Novel Object Categories Shubham Tulsiani, João Carreira, Jitendra Malik
ICCV, 2015 pdf bibtex code
@inProceedings{poseInductionTCM15,
author = {Shubham Tulsiani and
Jo{\~{a}}o Carreira and
Jitendra Malik},
title = {Pose Induction for Novel Object Categories},
year={2015},
booktitle={International Conference on Computer Vision (ICCV)}
}
Amodal Completion and Size Constancy in Natural Scenes
Abhishek Kar, Shubham Tulsiani, João Carreira, Jitendra Malik
ICCV, 2015 pdf bibtex
@inProceedings{amodalKTCM15,
author = {Abhishek Kar and
Shubham Tulsiani and
Jo{\~{a}}o Carreira and
Jitendra Malik},
title = {Amodal Completion and Size Constancy in Natural Scenes},
year={2015},
booktitle={International Conference on Computer Vision (ICCV)}
}
Viewpoints and Keypoints Shubham Tulsiani, Jitendra Malik
CVPR, 2015 pdf bibtex code
@inProceedings{vpsKpsTulsianiM15,
author = {Shubham Tulsiani and Jitendra Malik},
title = {Viewpoints and Keypoints},
year={2015},
booktitle={Computer Vision and Pattern Recognition (CVPR)}
}
Category-Specific Object Reconstruction from a Single Image
Abhishek Kar*, Shubham Tulsiani*, João Carreira, Jitendra Malik
CVPR, 2015 (Best Student Paper Award) pdf project page bibtex code
@inProceedings{shapesKarTCM15,
author = {Abhishek Kar and
Shubham Tulsiani and
Jo{\~{a}}o Carreira and
Jitendra Malik},
title = {Category-Specific Object Reconstruction from a Single Image},
year={2015},
booktitle={Computer Vision and Pattern Recognition (CVPR)}
}
Virtual View Networks for Object Reconstruction
João Carreira, Abhishek Kar, Shubham Tulsiani, Jitendra Malik
CVPR, 2015 pdf bibtex video code
@inProceedings{vvnCarreiraKTM15,
author = {Jo{\~{a}}o Carreira and
Abhishek Kar and
Shubham Tulsiani and
Jitendra Malik},
title = {Virtual View Networks for Object Reconstruction},
year={2015},
booktitle={Computer Vision and Pattern Recognition (CVPR)}
}
2013
A colorful approach to text processing by example
Kuat Yessenov, Shubham Tulsiani, Aditya Menon, Robert C Miller, Sumit Gulwani, Butler Lampson, Adam Kalai
UIST, 2013 pdf bibtex
@inproceedings{yessenov2013colorful,
title={A colorful approach to text processing by example},
author={Yessenov, Kuat and
Tulsiani, Shubham and
Menon, Aditya and
Miller, Robert C and
Gulwani,Sumit and
Lampson, Butler and
Kalai, Adam},
booktitle={UIST},
pages={495--504},
year={2013},
organization={ACM}
}