|
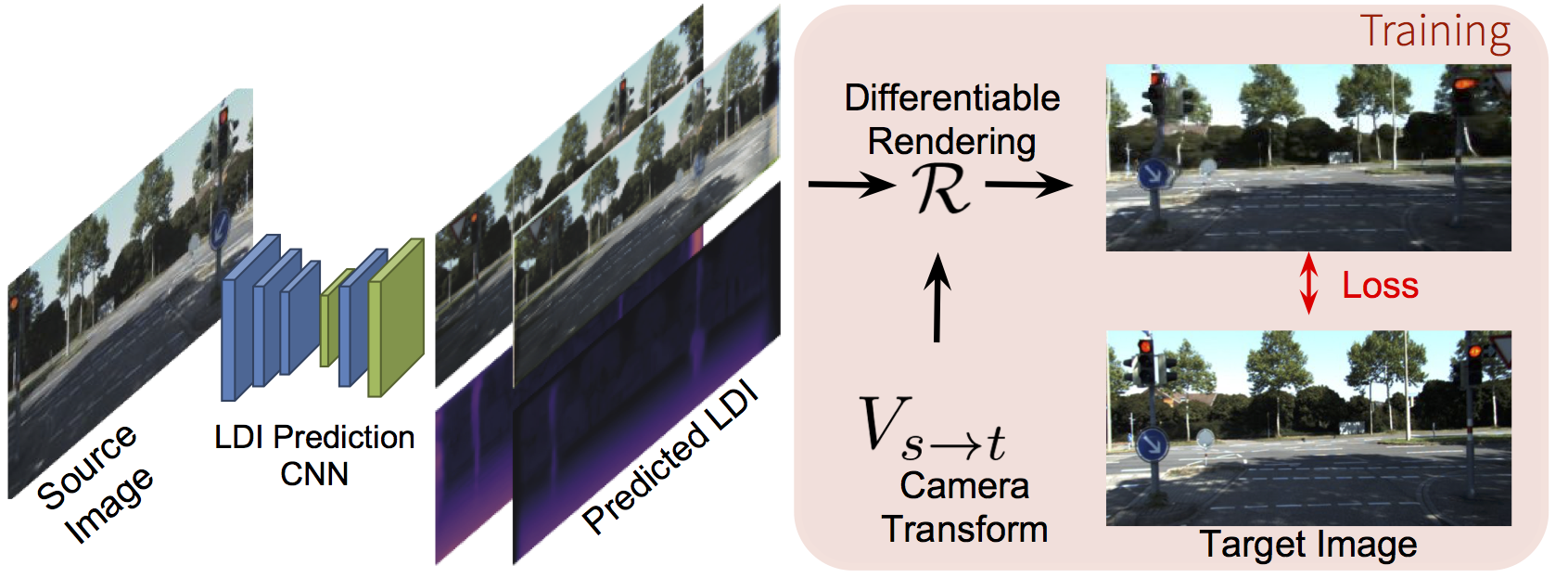
In this work we go beyond 2.5D shape representations and learn to predict layered scene representations from single images that capture more complete scenes, including hidden objects. On the right, we show our method's predicted 2-layer texture and shape for the highlighted area: a, b) show the predicted textures for the foreground and background layers respectively, and c,d) depict the corresponding predicted inverse depth. Note how both predict structures behind the tree, such as the continuation of the building.
|