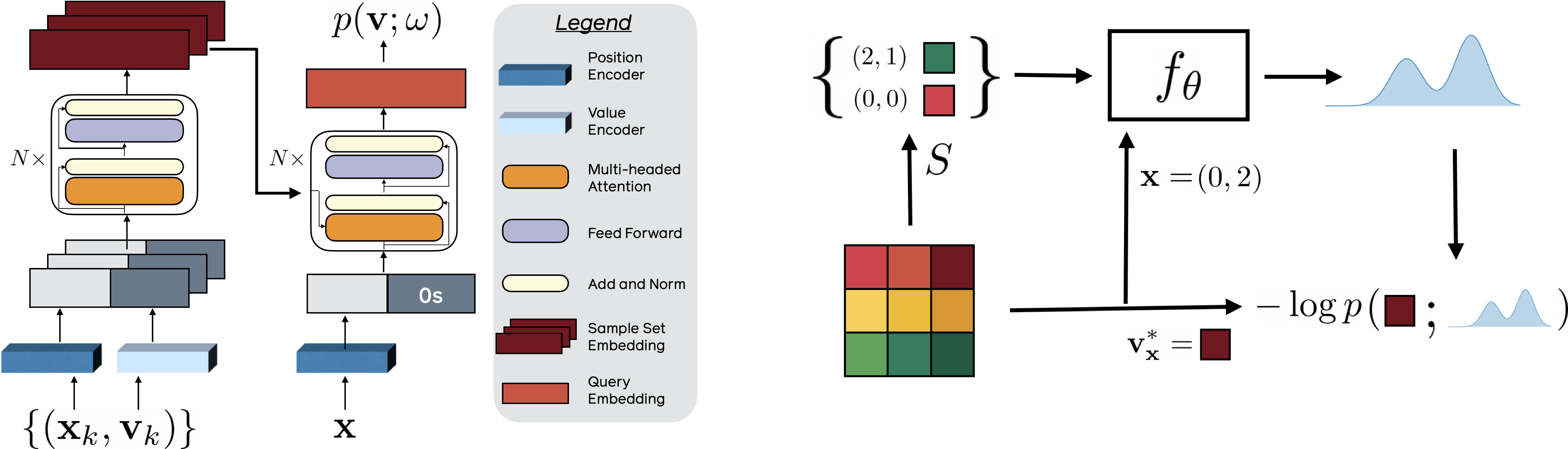
|
|
|
|
|
|
|
|
|
|
|








|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
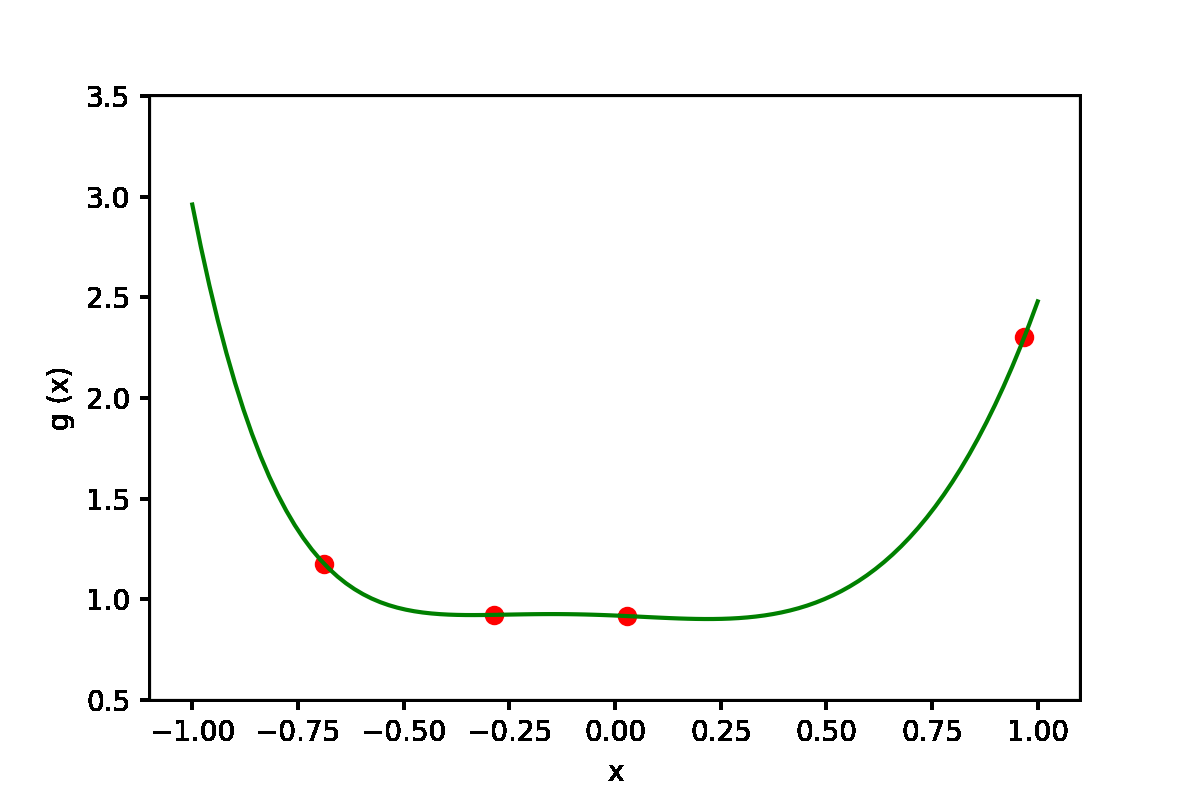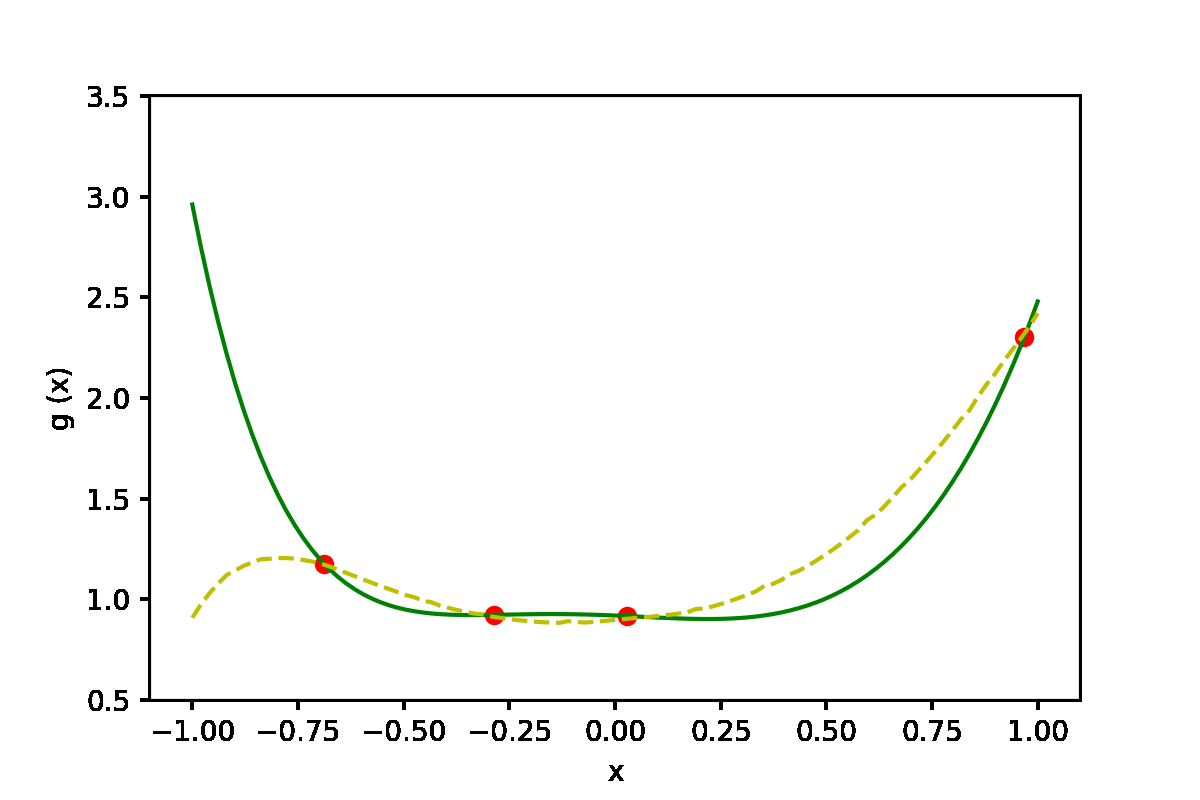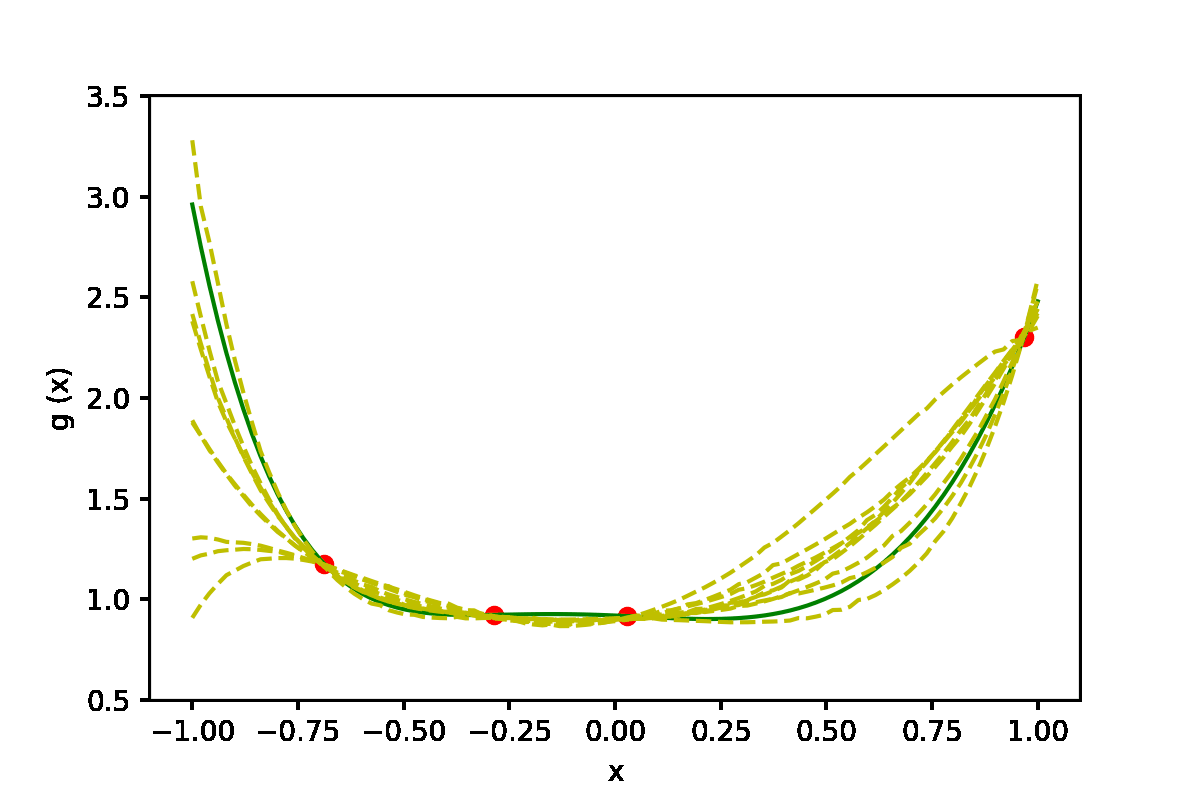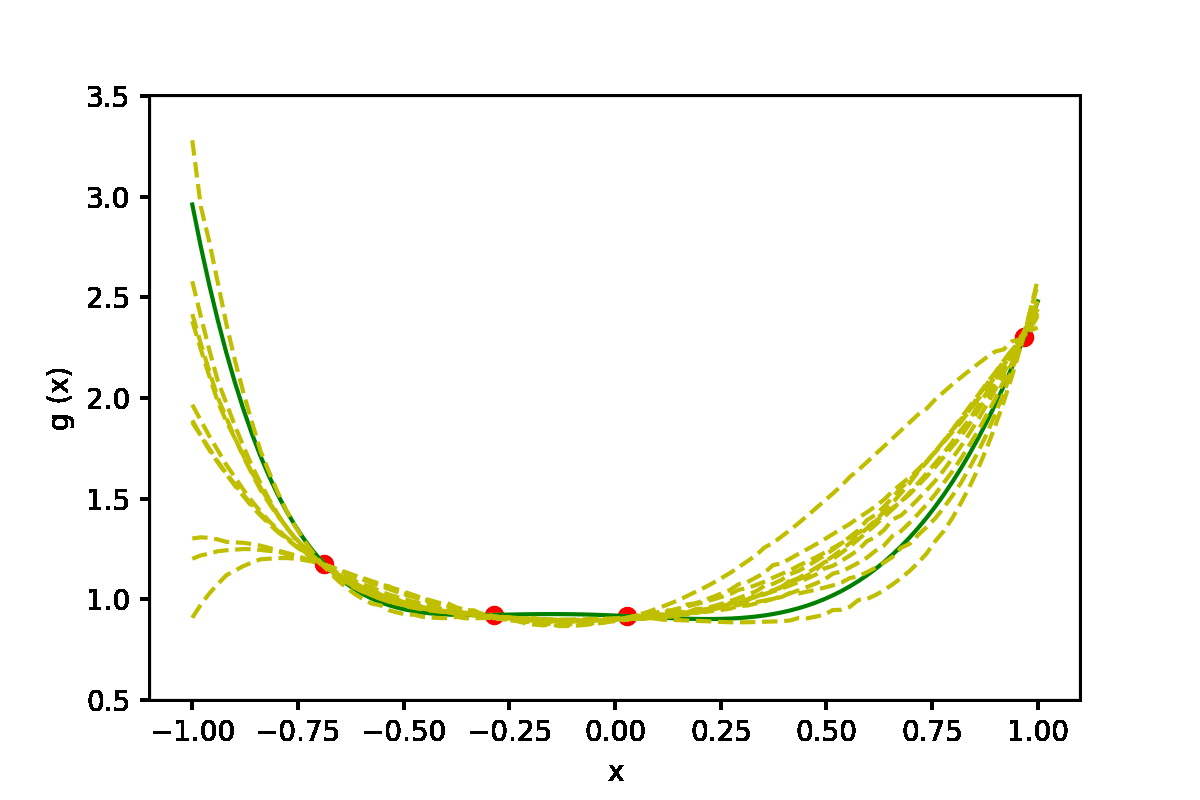
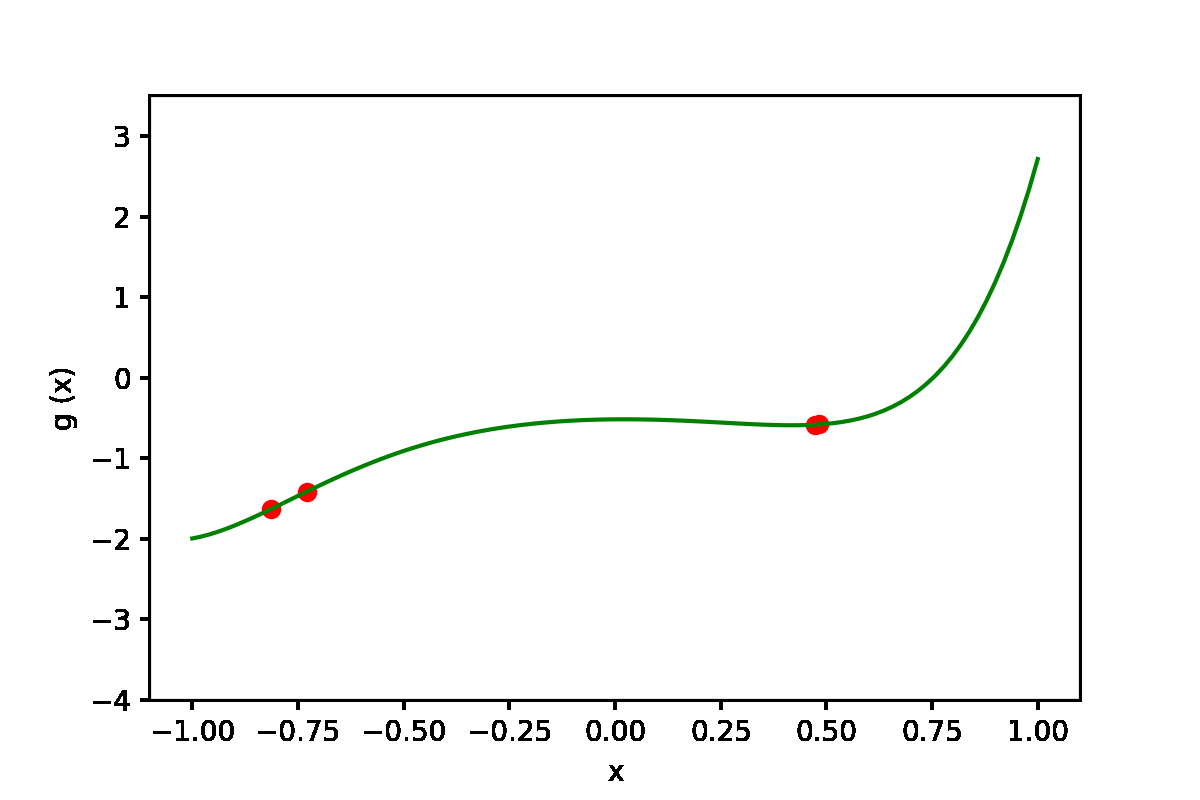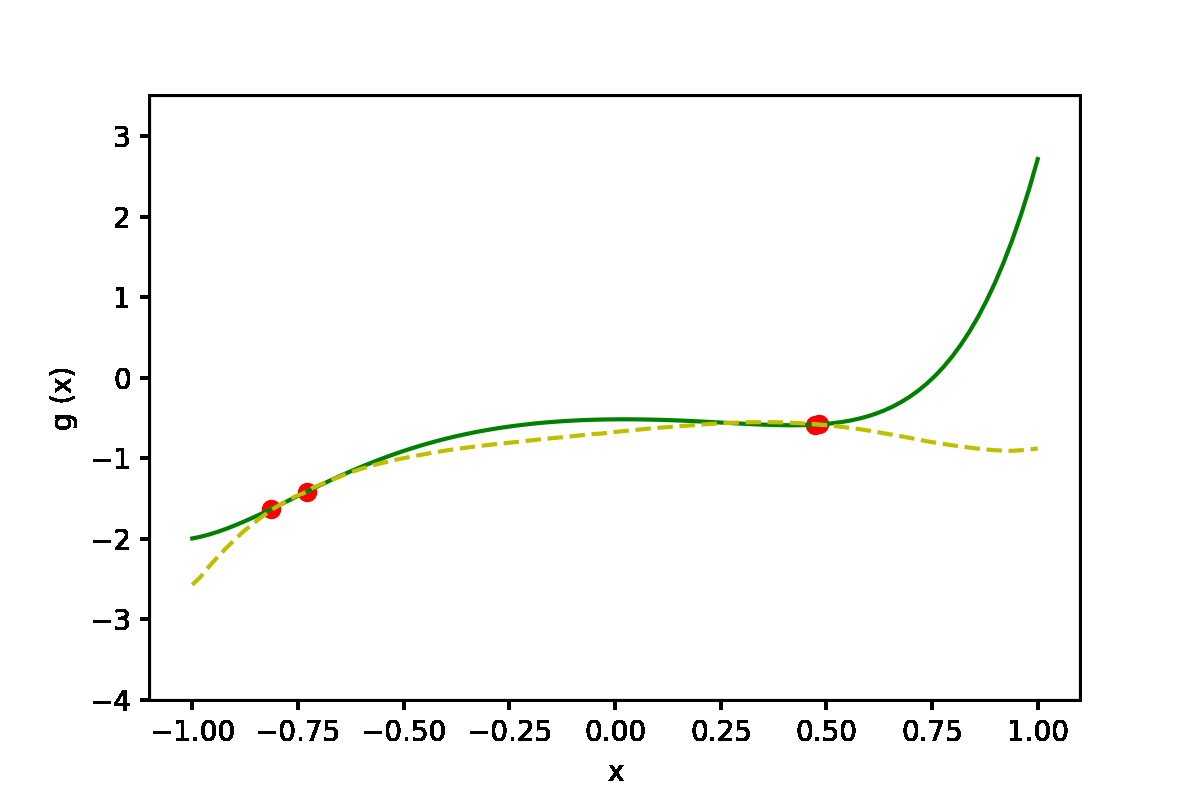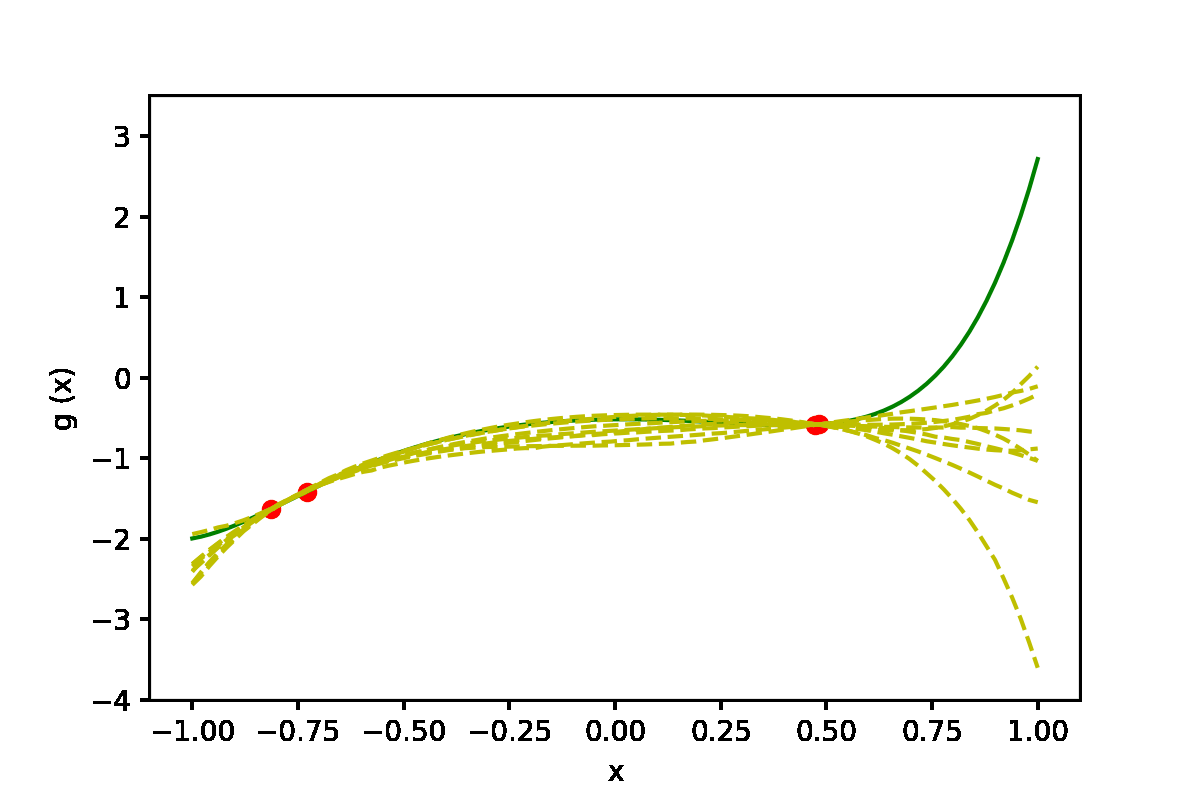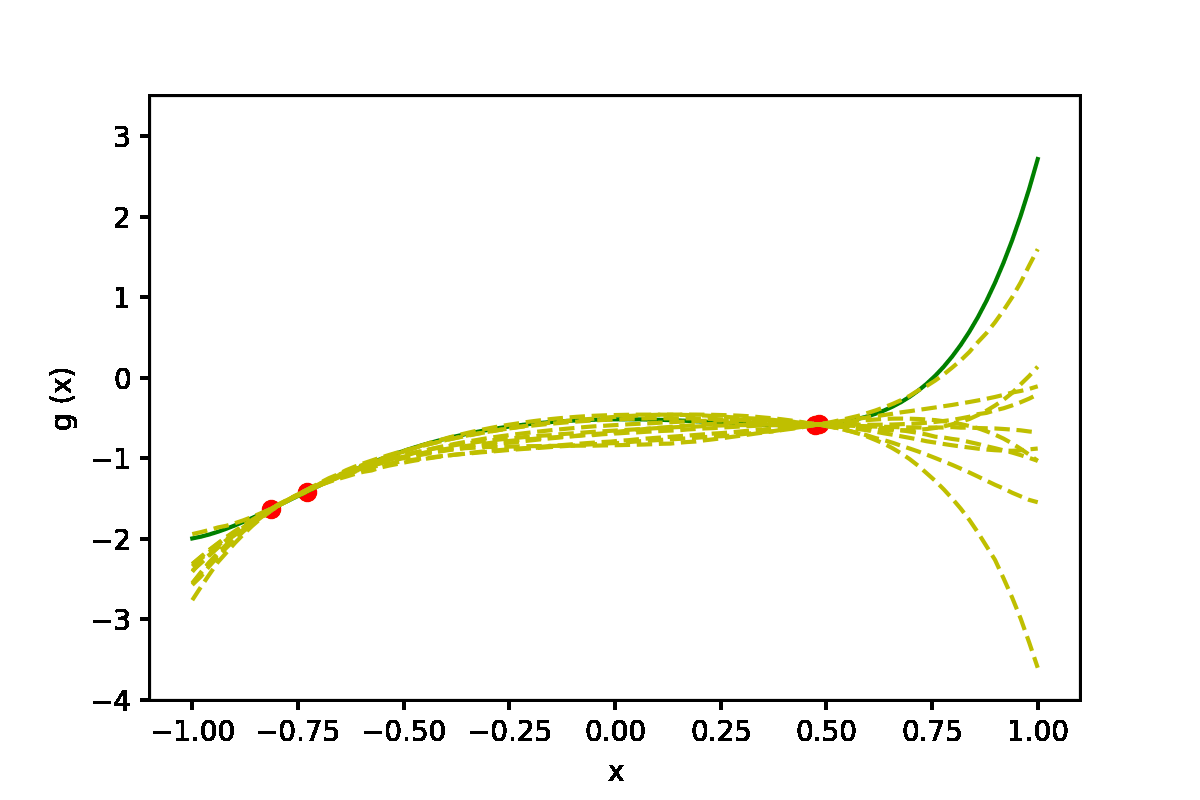
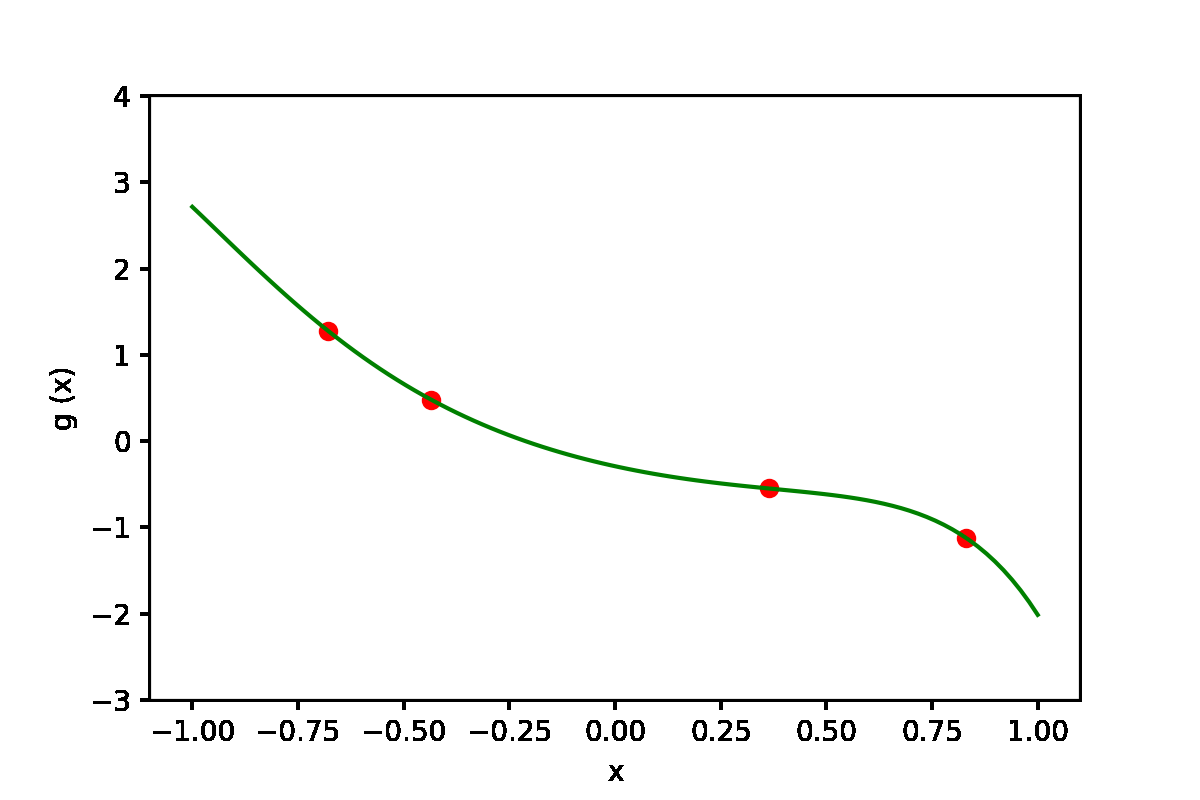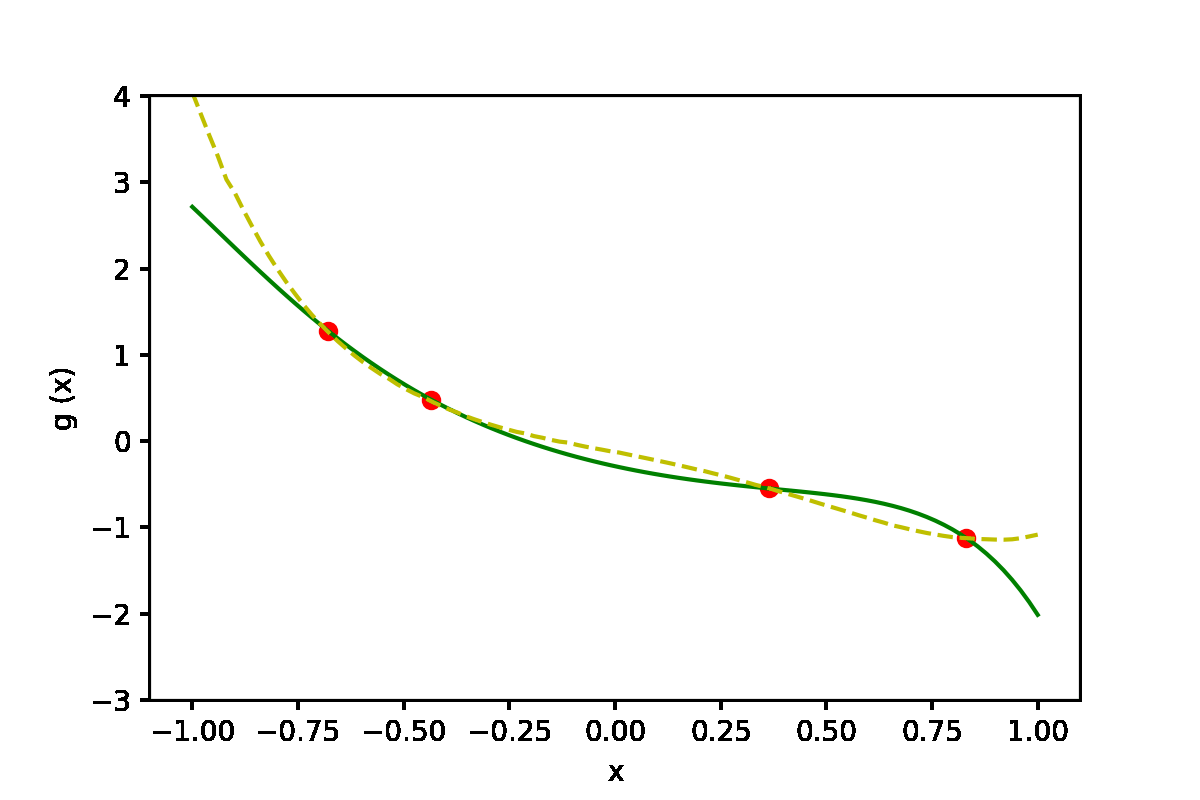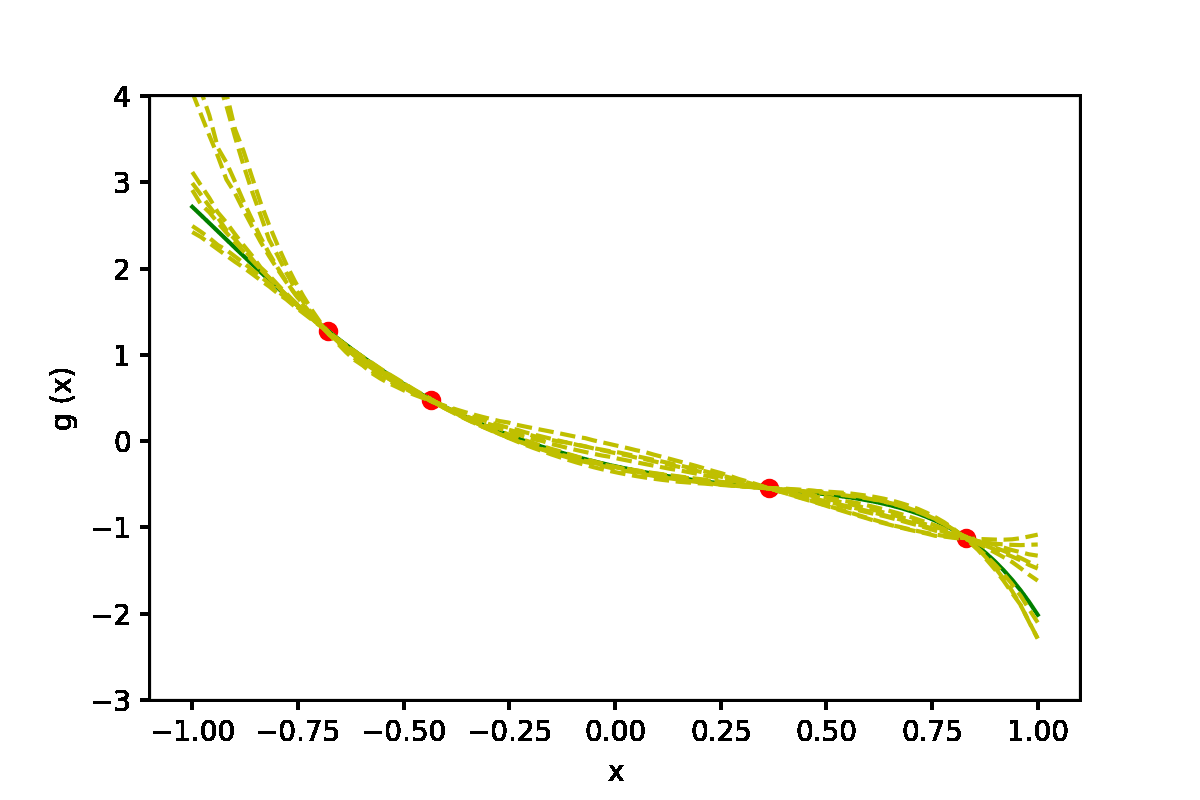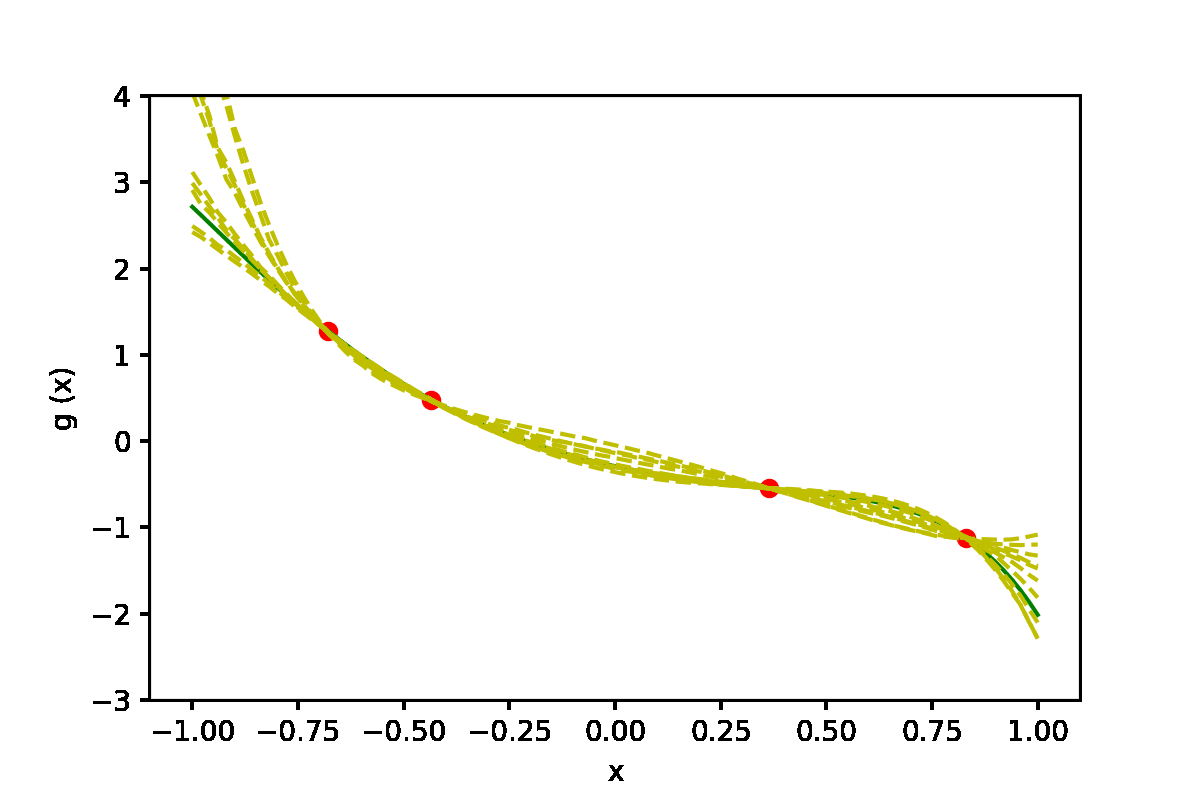
|
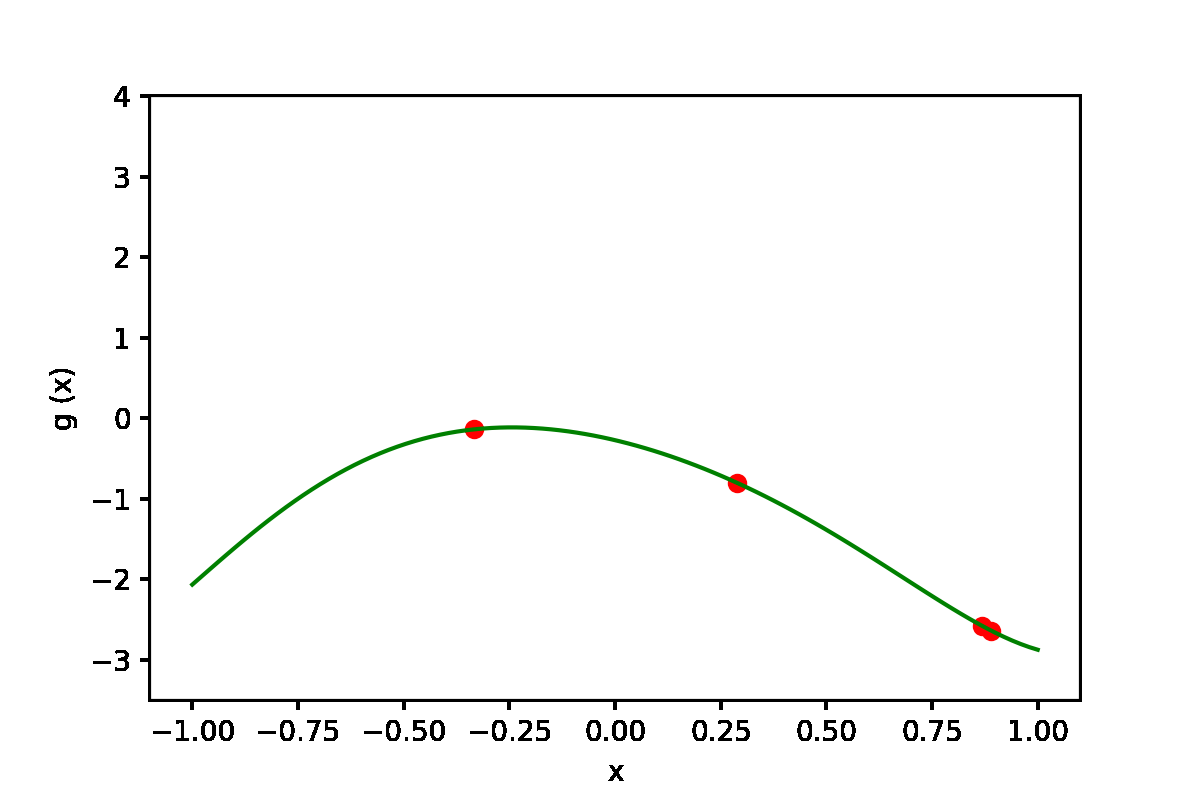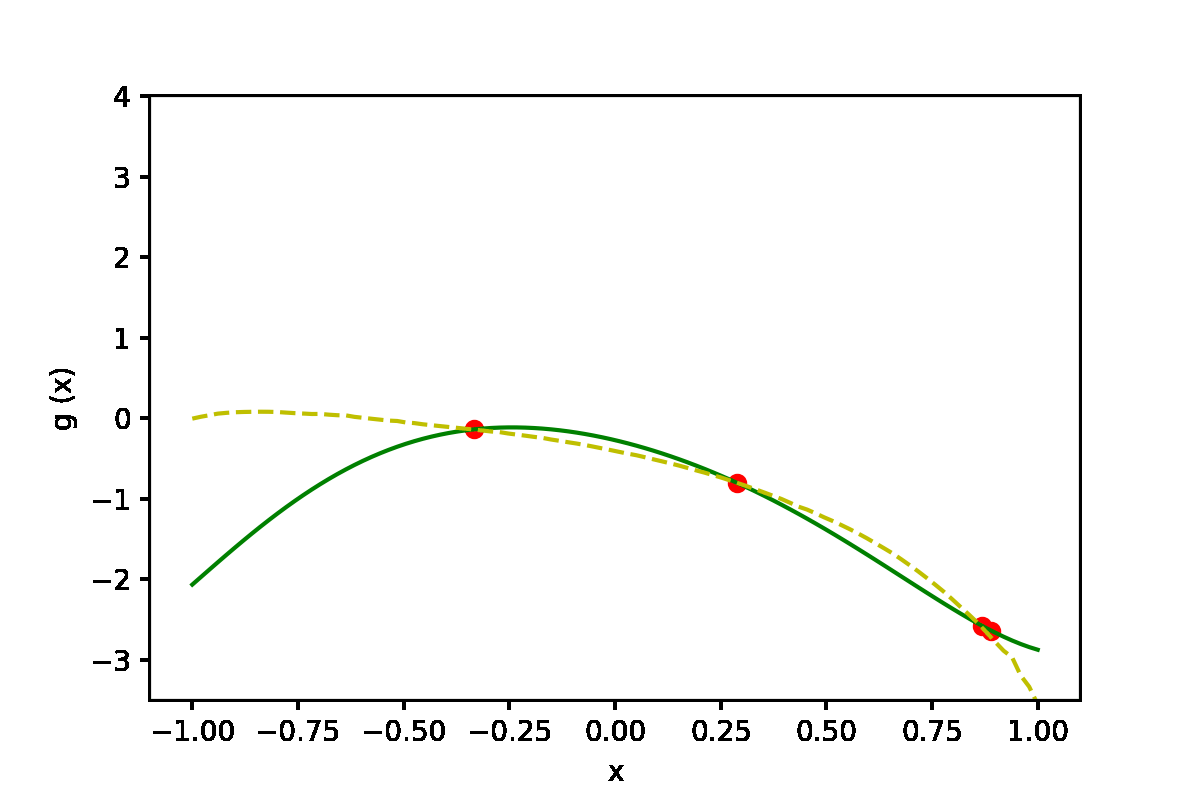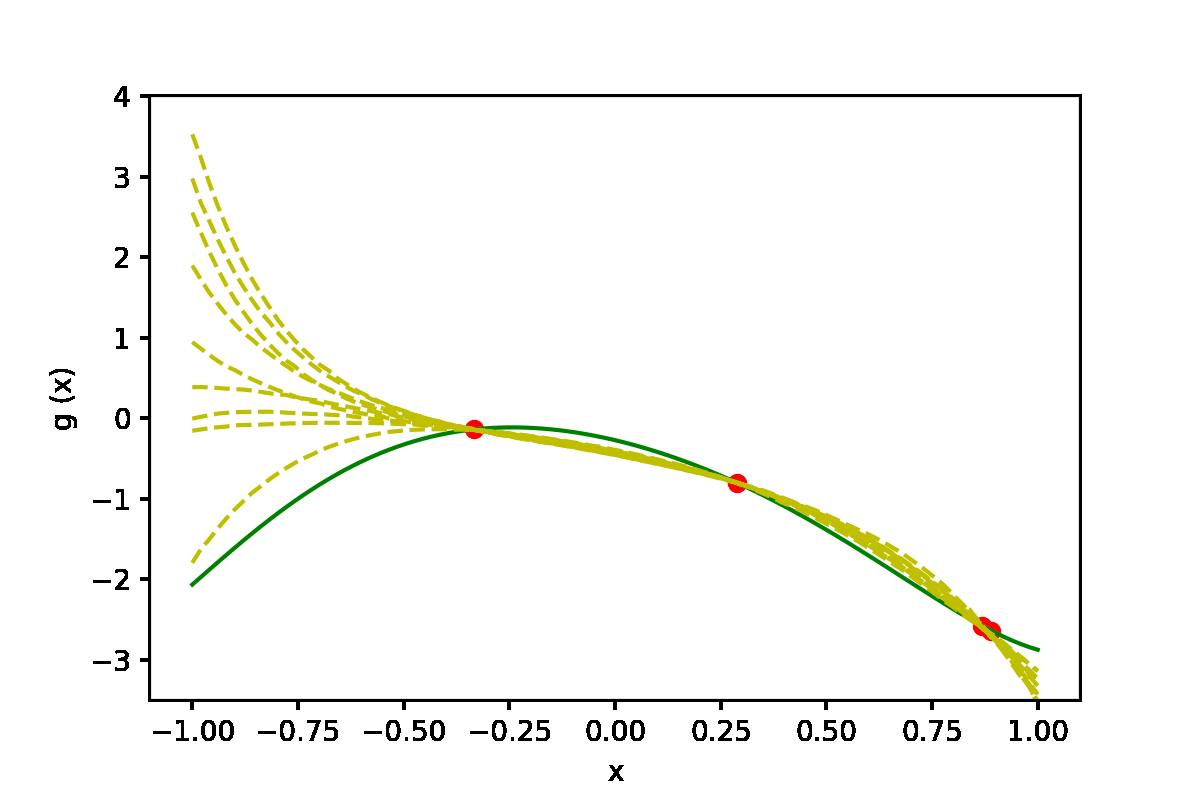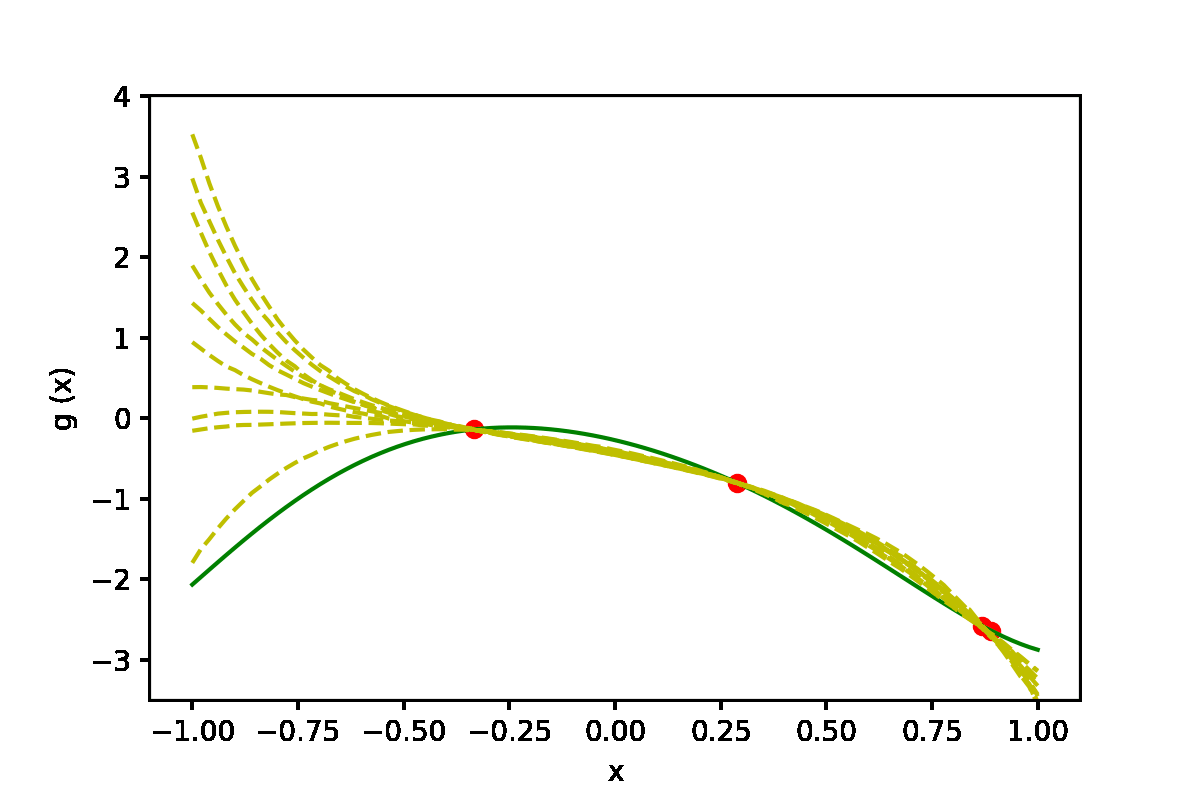
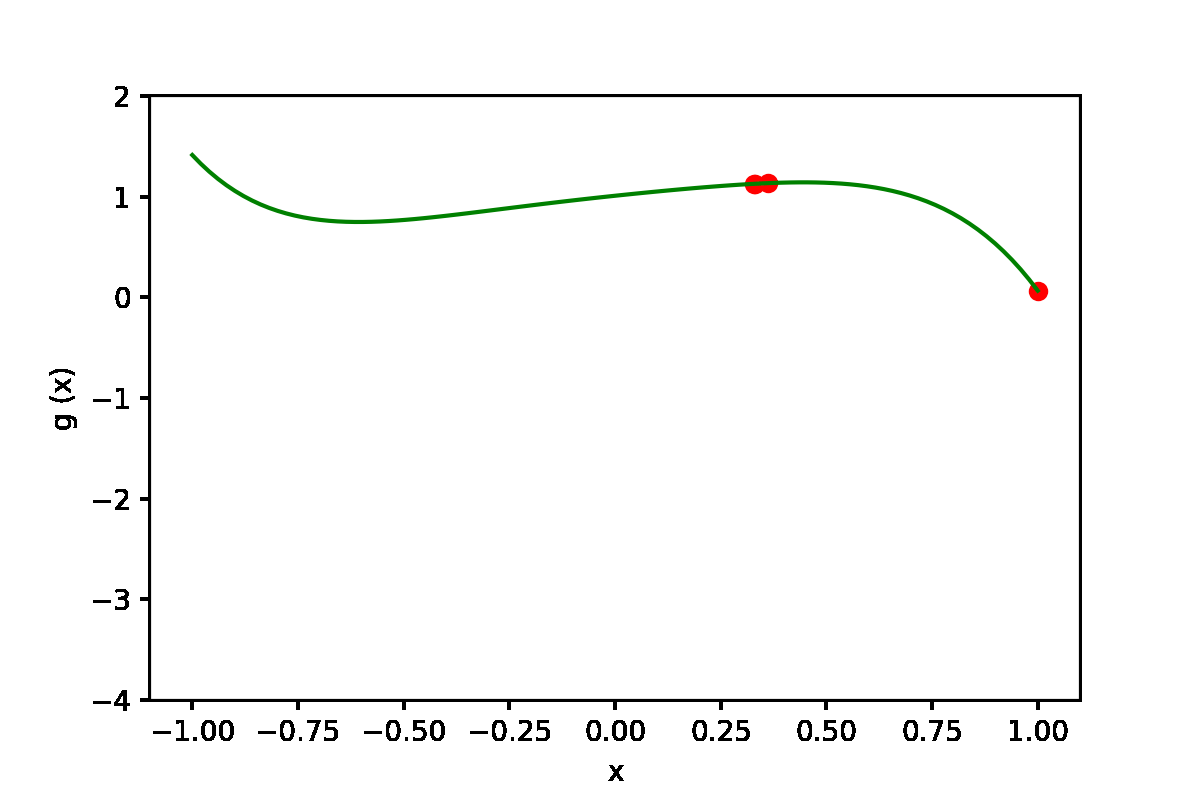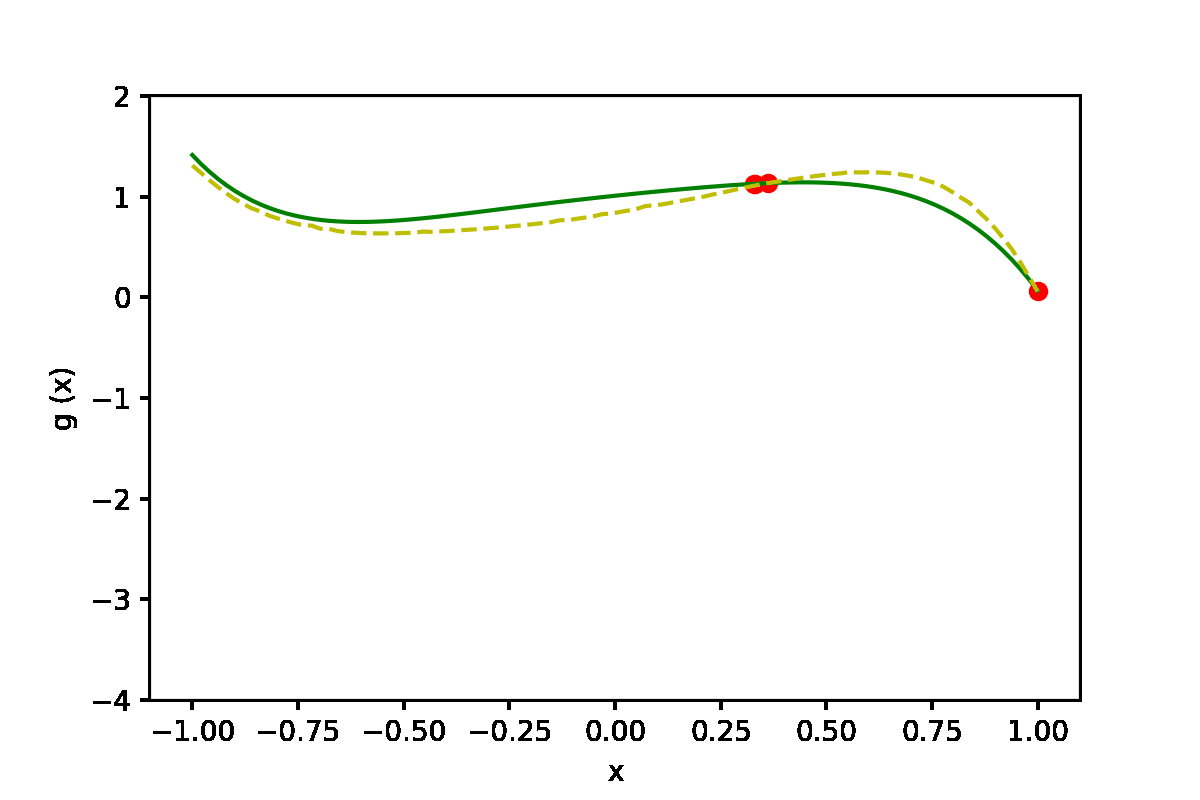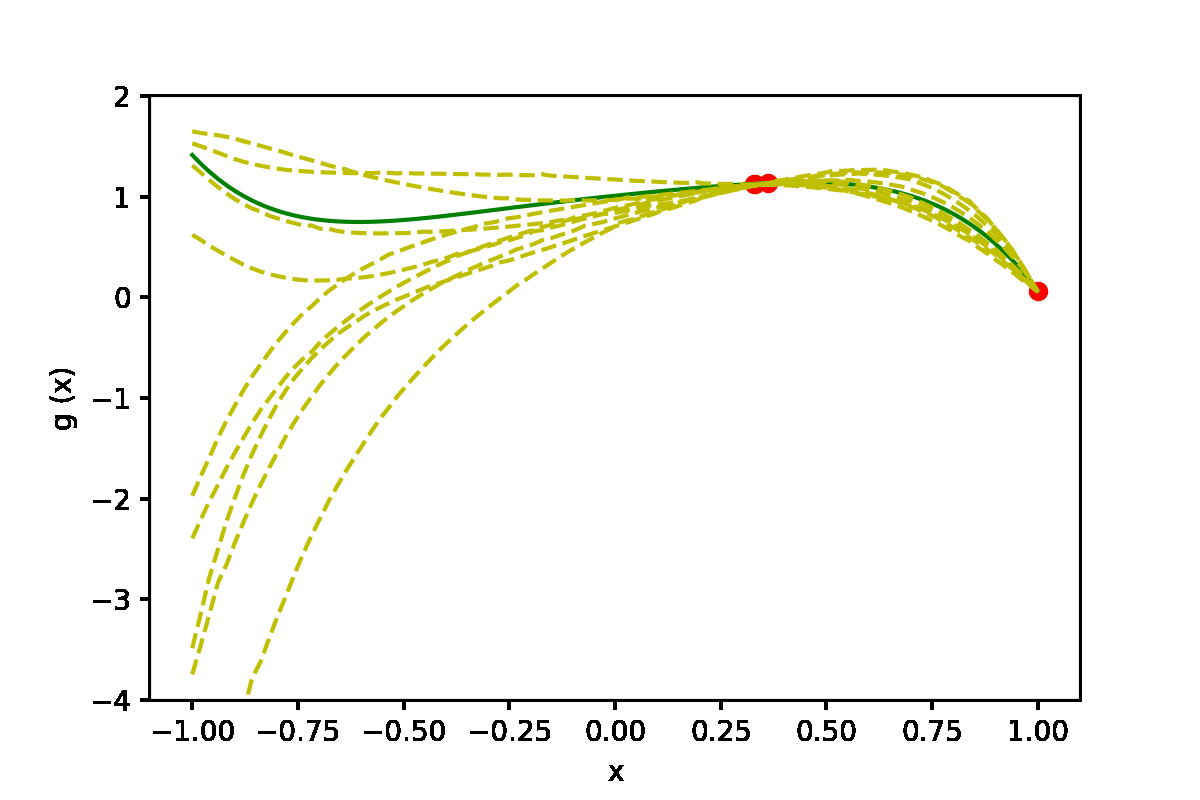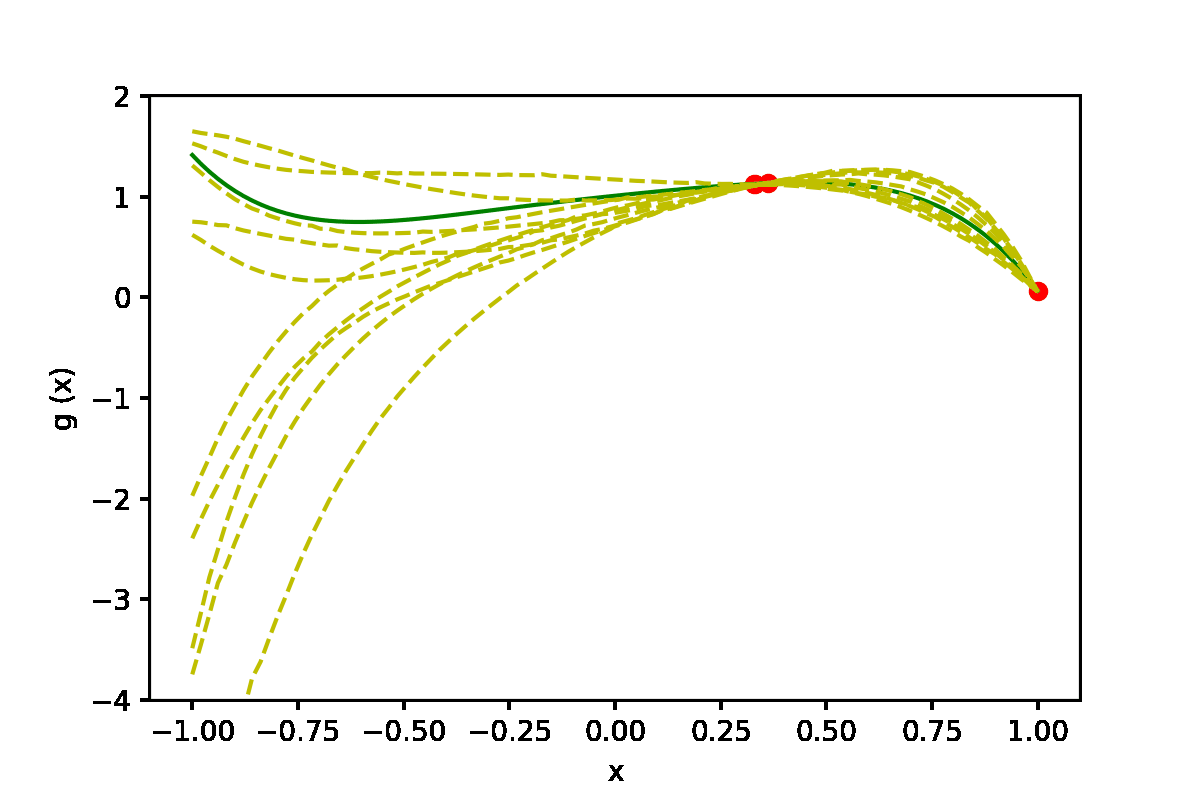
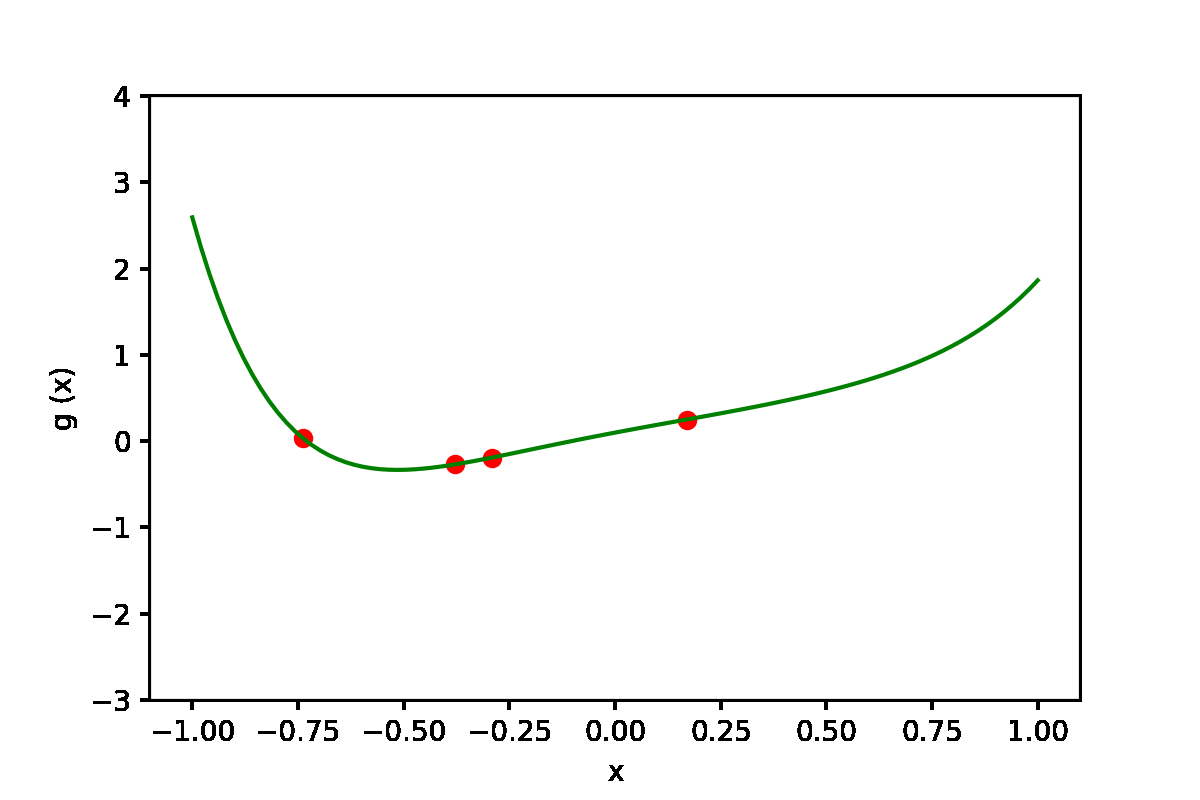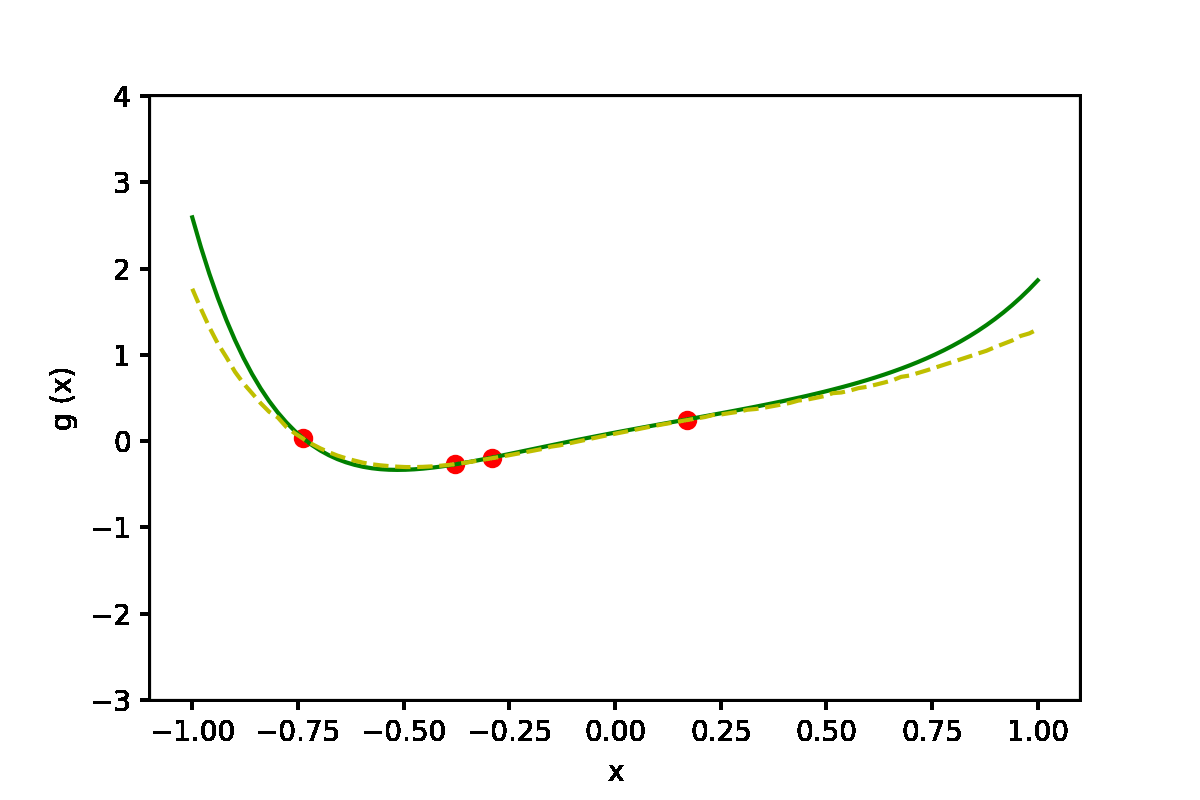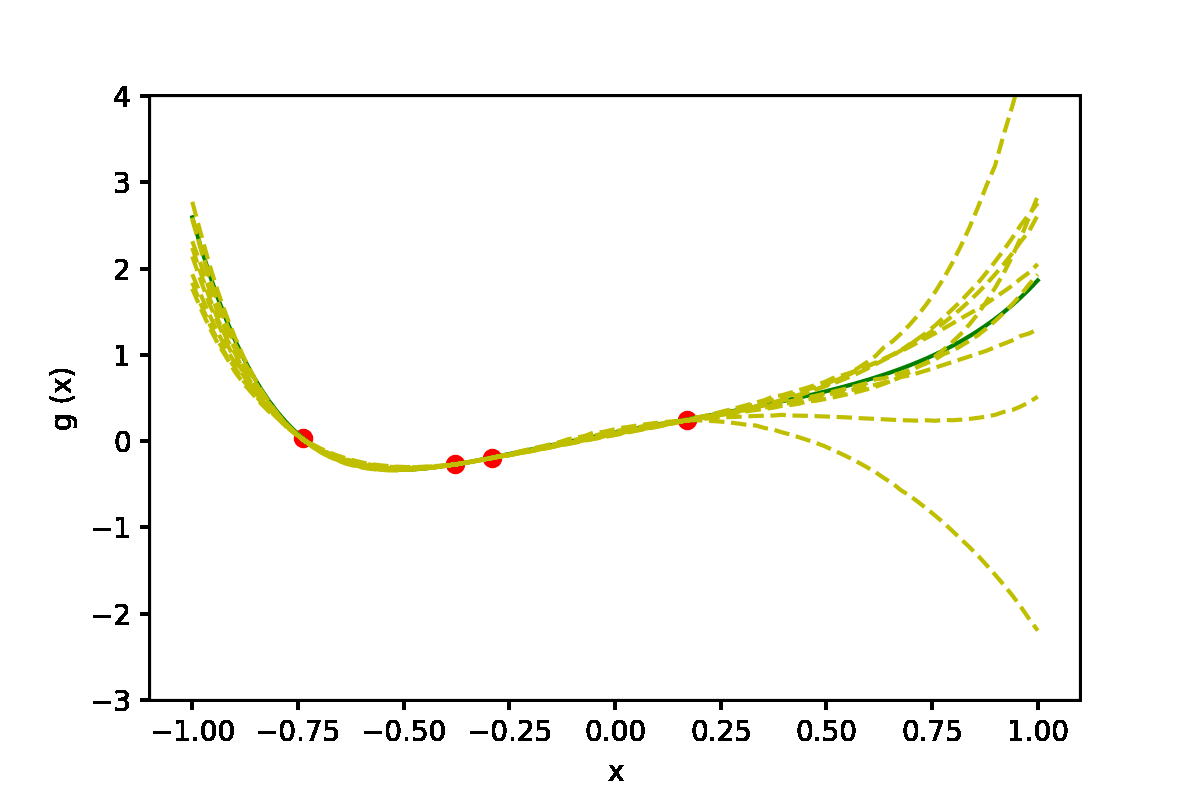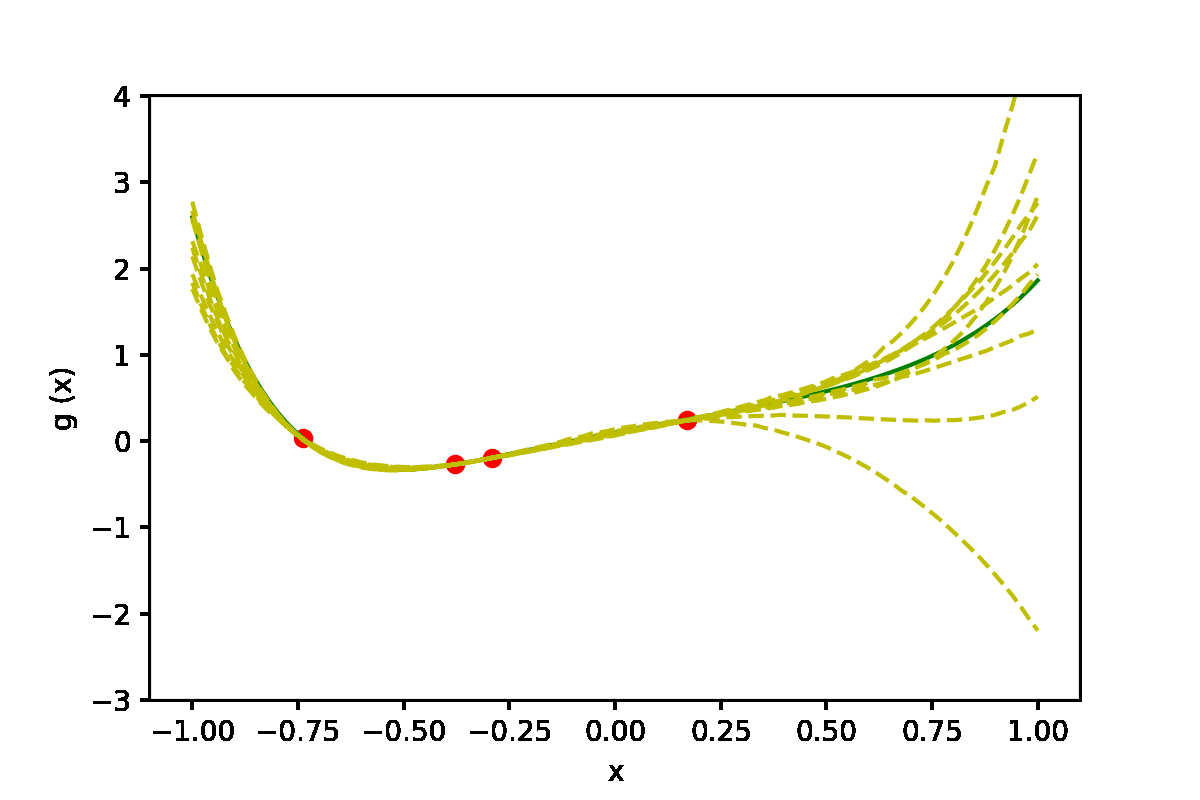
|
| GT |












|
| Nearest Neighbor Visualization of Initially Observed Pixels |












|
| Generated Videos |












|












|












|