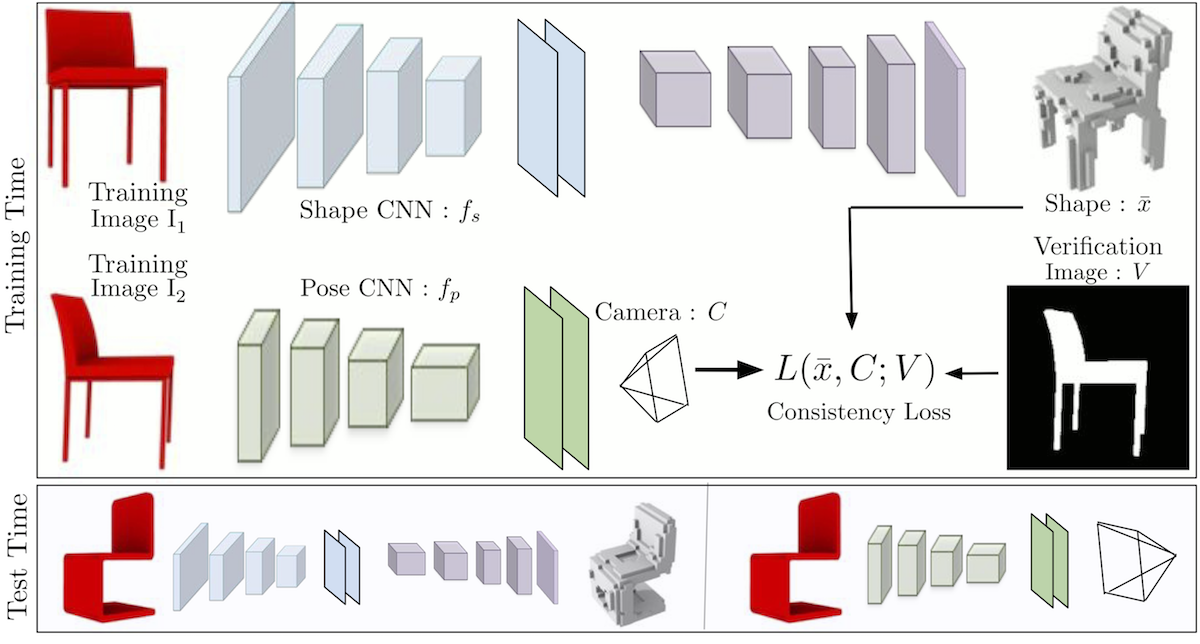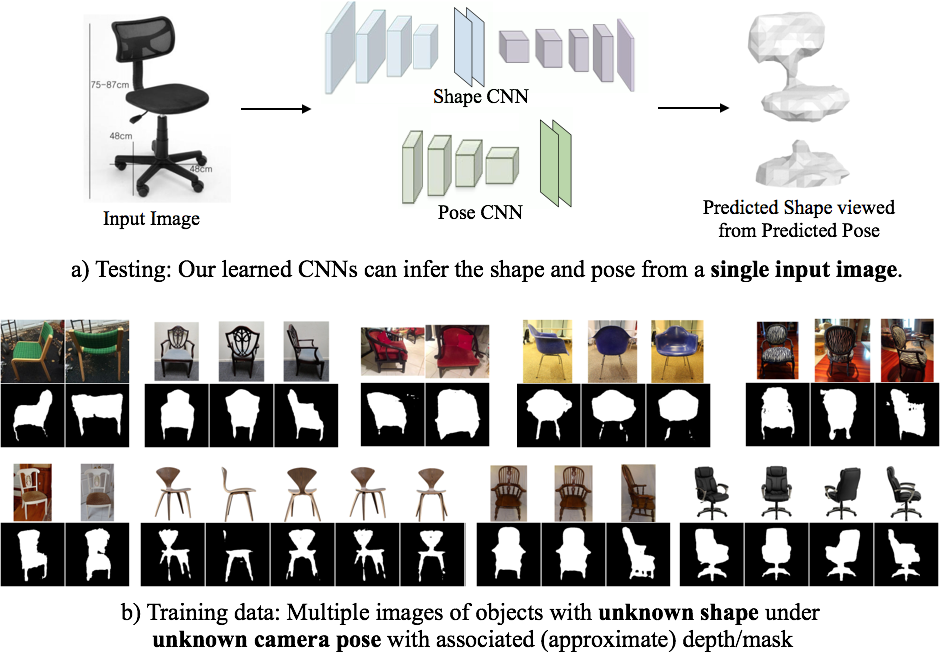
|
|
|
|
|
|
|
|
|
|
|
 |
Tulsiani, Efros, Malik. Multi-view Consistency as Supervisory Signal for Learning Shape and Pose Prediction. CVPR, 2018. |
 |
|
Acknowledgements |